本文由 发布,转载请注明出处,如有问题请联系我们! 发布时间: 2021-05-17Elasticsearch入门,看这一篇就够了
加载中Elasticsearch新手入门,看这一篇就可以了
文件目录- 序言
- 数据分析工具
- kibana
- kibana 的安裝
- kibana 配备
- kibana 的运行
- Elasticsearch 新手入门实际操作
- 实际操作 index
- 建立 index
- 数据库索引别称有什么作用
- 删除索引
- 查看数据库索引
- exist 数据库索引
- 建立 index
- 实际操作 document
- 插进 document
- 查看 document
- 删掉 document
- 升级 document
- 应用脚本制作升级 document
- reindex 实际操作
- 实际操作 index
- 汇总
序言
Elasticsearch 是由 Shay Banon 进行的一个开源系统的分布式系统站内搜索,自 2010 年 2 月公布至今,该新项目已发展趋势变成检索和数据统计分析解决方法行业中至关重要的一员,广泛运用于各大论坛。
数据分析工具
如同关联型数据库查询一样,大家应用 Elasticsearch 时也必须一款数据分析工具,最常见的便是 kibana,而这也是 ELK 建立中的 K,剩余的 L 便是 Logstash。
kibana
Kibana 是一款十分强劲的专用工具,应用 kibana,我们可以做下列三件事:
- 检索,观查和维护: 从发觉文本文档到剖析日志再到发觉网络安全问题,Kibana是您浏览这种作用以及他作用的门户网。
- 数据可视化即数据统计分析:剖析在数据图表,仪表盘,地形图等发觉的数据信息,并将他们组成到汽车仪表板。
- 管理方法监管即维护
Elastic Stack:管理方法数据库索引和获取管路,监控Elastic Stack群集的运行情况,并操纵什么客户能够 浏览什么作用。
kibana 的安裝
kibana 的安裝也非常简单,点一下这儿免费下载相匹配版本号,并开展缓解压力,缓解压力后的主目录即是 $KIBANA_HOME 途径:

一样的,大家必须进到 config 文件目录下,改动 kibana 的环境变量 kibana.yml。
kibana 配备
和 Elasticsearch 一样,安裝好 kibana 以后,大家也必须对在其中一些关键的环境变量开展配备:
- elasticsearch.hosts
配备必须联接的 Elasticsearch 服务项目,假如配备好几个服务项目,则务必归属于同一个 Elasticsearch 群集,初始值为:
elasticsearch.hosts: ["http://localhost:9200"]
- server.name
标志当今 kibana 的唯一案例,默认设置是IP地址,这一仅仅具有一个叙述标志功效。
- server.host
特定 kibana 的IP地址,默认设置 localhost,表明只容许该设备浏览。假如必须远程桌面连接,则必须将此配备改动为外网地址 ip 详细地址或是网站域名等非当地回环地址,或是能够 应用 0.0.0.0 容许全部远程控制服务器联接。
- server.port
配备 kibana 的端口,默认设置是 5601。
- elasticsearch.requestTimeout
等候后台管理或是等候 Elasticsearch 回应的ms数,初始值为:30000.
- elasticsearch.pingTimeout
等候 Elasticsearch 的 ping 的回到ms数,初始值相当于 elasticsearch.requestTimeout 配备的時间。
- elasticsearch.username 和 elasticsearch.password
假如 Elasticsearch 配备了账户密码,则必须在这儿配备上账户和登陆密码。
- path.data
Kibana 中储存沒有储存在 Elasticsearch 中的分布式锁数据信息的途径。
- logging.dest
特定 log 途径,默认设置为 stdout。
- server.basePath
特定浏览 kibana 的基本途径,默认设置为 /,一般假如要根据 Nginx 等分布式数据库开展代理商得话,会设定基本途径。
- server.rewriteBasePath
跳转以后途径是不是保存 server.basePath 途径,在 kibana 6.3 及更早的版本号默认设置是 false,在 kibana 7.0 以后的版本号中默认设置为 true。
kibana 的运行
配备完只需环境变量以后,就可以进到 bin 文件目录运行命令 ./kibana 运行 kibana,假如要想在后台管理运行,则能够 运行命令 ./kibana &。
运行以后就可以浏览 kibana:http://ip:5601/{basePath}
浏览以后,开启左侧的 Dev Tools,就可以逐渐实行归属于 Elasticsearch 的 "sql 句子" 开展增删等实际操作了:
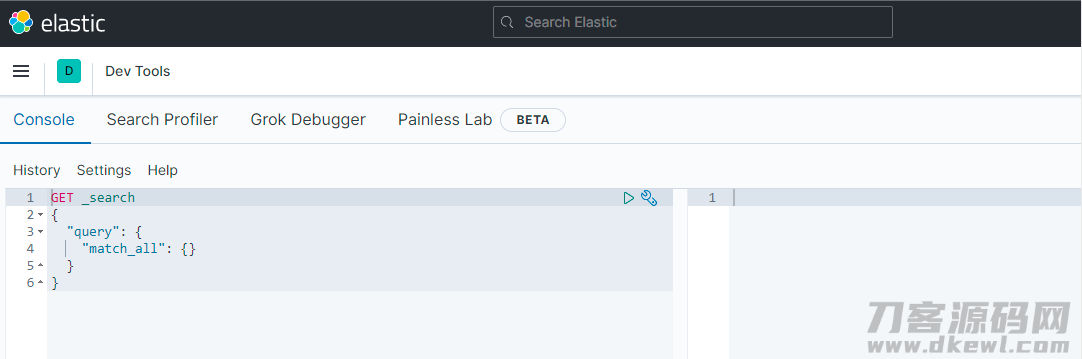
除开 Dev Tools 以外,kibana 也有很多别的强劲的作用,大伙儿能够 自主去试着实际操作。
Elasticsearch 新手入门实际操作
历经一系列实际操作,总算能够 逐渐实际操作 Elasticsearch 了,Elasticsearch 中的 API 遵照了 REST 设计风格,运用其给予的 REST API 能够 管理方法数据库索引,变更案例主要参数,查验连接点和群集情况,而且对数据库索引中的文本文档数据信息数据信息开展 CRUD 实际操作。
实际操作 index
数据库索引等同于数据库查询,因此 大家先来学习培训一下数据库索引的操作过程。
建立 index
创建索引一般应用 PUT 方式 :
PUT /my-index-001
如果有界定 mapping,则能够 在创建索引的另外携带 mapping:
PUT /my-index-002
{
"mappings": {
"properties": {
"field1": { "type": "text" }
}
}
}
另外,创建索引的情况下还能够给数据库索引建立别称:
PUT /my-index-003
{
"mappings": {
"properties": {
"field1": { "type": "text" }
}
},
"aliases": {
"alias_name": {}
}
}
拥有别称以后,查看数据库索引能够 应用别称开展查看。
数据库索引别称有什么作用
数据库索引别称实际上在一些情景的情况下是十分有效的,例如在我们发布以后,假如由于一些业务流程变化,造成必须改动字段名,那麼此刻在 Elasticsearch 中就必须复建数据库索引。复建数据库索引的情况下我们可以特定一个同样的别称,而如果我们的编码中便是根据别称开展查看时,此刻复建数据库索引后就可以完成无缝衔接了。
删除索引
删除索引选用 DELETE 方式 。
DELETE /my-index-0001
查看数据库索引
查看数据库索引信息内容选用 GET 方式 ,这一能够 回到数据库索引的 setting,mapping,aliases 及其分块等信息内容。
GET /my-index-001
exist 数据库索引
分辨数据库索引是不是存有,选用的是 HEAD 方式 。
HEAD /my-index-001
- clone index
复制数据库索引以前,务必要先把一个数据库索引改为写保护(另外需确保群集情况为翠绿色):
PUT /my-index-004/_settings
{
"settings": {
"index.blocks.write": true
}
}
改为写保护后,就可以应用 POST 方式 开展复制数据库索引:
POST /my-index-004/_clone/cloned-my-index-004
实际操作 document
学会了 index 的操作过程,下面就就可以学习培训一下 document(数据信息) 的操作过程。
插进 document
插进 document 选用的是 POST 方式 :
POST /my-index-001/_doc/?pretty{ "@timestamp": "2099-11-15T13:12:00", "message": "GET /search HTTP/1.1 200 1070000", "user": { "id": "kimchy" }}
上边的句子中由于沒有转化成 id,因此 Elasticsearch 会自动生成一个 id 值。
插进特定 id 文本文档,则能够 应用 _resource 句子:
PUT my-index-001/_create/1{ "@timestamp": "2099-11-15T13:12:00", "message": "GET /search HTTP/1.1 200 1070000", "user": { "id": "kimchy" }}
或是特定 op_type=create:
PUT my-index-001/_doc/2?op_type=create{ "@timestamp": "2099-11-15T13:12:00", "message": "GET /search HTTP/1.1 200 1070000", "user": { "id": "kimchy" }}
查看 document
简易的查看句子能够 应用 GET 方式 :
GET /my-index-001/_search
查看以后获得以下結果(大家的源数据信息在 hits 里边,外边的字段名是 Elasticsearch 内置的通用字段):
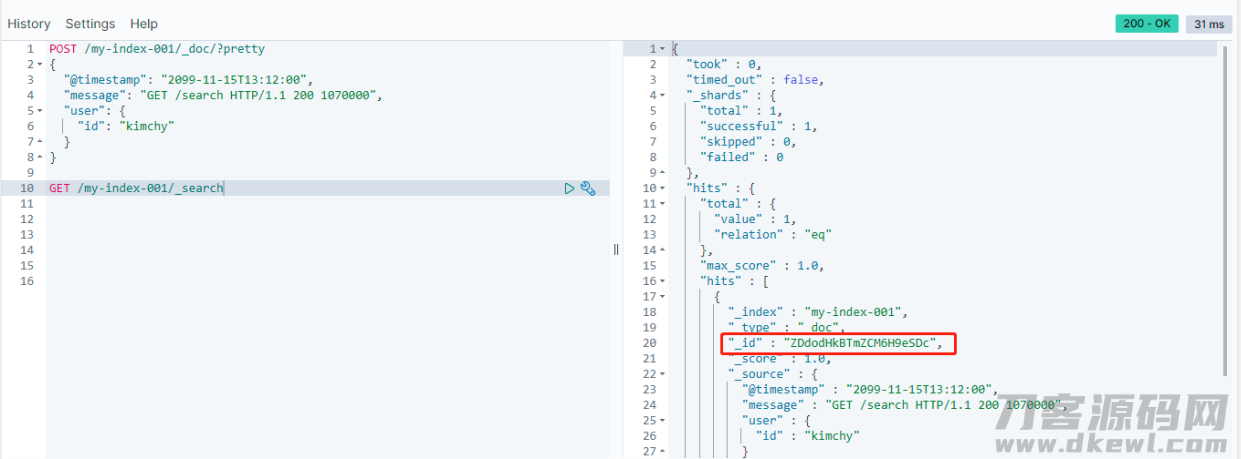
假如想只查看特殊 id 文本文档则能够 应用以下句子:
GET /my-index-001/_doc/1
而如果我们想特定回到字段名或是特定不回到字段名,则能够 应用 _source 等主要参数(下边他们则表明只回到 *.id 的字段名且不回到 @timestamp 字段名):
GET my-index-001/_doc/1?_source_includes=*.id&_source_excludes=@timestamp
有一些有时假如对于我们自己储存的字段名,一个都不愿回到,则能够 应用以下句子:
GET my-index-001/_doc/1?_source=false
删掉 document
删掉文本文档应用 DELETE 方式 ,删掉英语的语法为:DELETE /<index>/_doc/<_id>。
特定 id 删掉,请求超时時间为 5 分鐘:
DELETE /my-index-001/_doc/1?timeout=5m
假如想删掉全部字段名,则能够 应用 delete_by_query 句子:
POST my-index-001/_delete_by_query{ "query": { "match_all": {} }}
一样的,delete_by_query 还可以特定标准删掉:
POST /my-index-001/_delete_by_query{ "query": { "match": { "user.id": "elkbee" } }}
升级 document
升级 document 一般应用 POST 方式 ,应用 _update 种类,下边大家来演试一个升级句子:
- 插进一条数据信息到
test数据库索引:
PUT test/_doc/1{ "name":"双子座孤狼", "age":18, "address":"广东省深圳市"}
- 对
name字段名开展升级:
POST test/_update/1{ "doc": { "name": "双子座孤狼2" }}
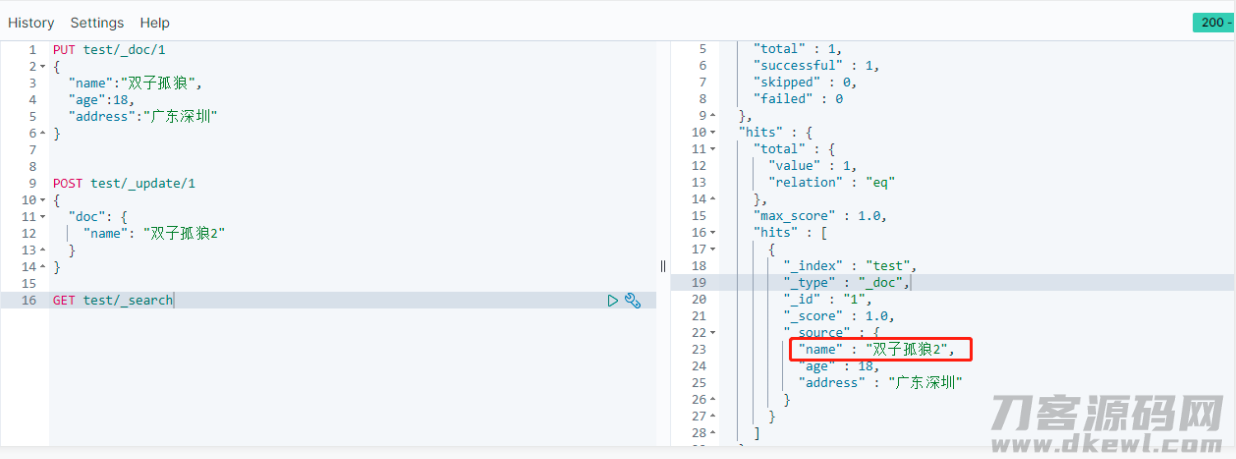
- 执行查询句子
GET test/_search开展查看,则发觉name字段名已被升级:
应用脚本制作升级 document
升级句子还能够应用 script 来完成更灵便的实际操作(以下则表明将 age 字段名提升 4):
POST test/_update/1{ "script" : { "source": "ctx._source.age = params.count", "lang": "painless", "params" : { "count" : 4 } }}
和 delete_by_query 句子一样,升级句子还可以应用 update_by_query 句子:
POST test/_update_by_query{ "script": { "source": "ctx._source.age = params.count", "lang": "painless", "params" : { "count" : 4 } }, "query": { "match": { "name": "双子座孤狼2" } }}
reindex 实际操作
有时大家必须将一个数据库索引的数据信息拷贝到另一个数据库索引,那麼此刻就可以应用 reindex 实际操作,这一实际操作和前边的 clone 实际操作的差别是 reindex 实际操作总是转移文本文档数据信息,而不容易将 setting,mapping及其分块等信息内容转移到新数据库索引,并且在实行 reindex 实际操作时不用将旧数据库索引设定为写保护情况。
POST _reindex?wait_for_completion=false{ "source": { "index": "old-index" }, "dest": { "index": "new-index" }}
wait_for_completion 主要参数默认设置为 true,表明当今实际操作会一直堵塞直至取得成功截止,假如到请求超时時间都还没进行则会出错,因此 假如信息量较为大能够 改动 wait_for_completion 主要参数为 false。
汇总
文中关键详细介绍了 kibana 的安裝及一些关键的配备,并根据 kibana 详细介绍了 Elasticsearch 中对 index 和 document 的一些基本上的增删实际操作。自然,假如要想深层次应用 Elasticsearch,这种句子是还不够的,Elasticsearch 的一些高级查询及剖析句子才算是 Elasticsearch 的关键。







