本文由 发布,转载请注明出处,如有问题请联系我们! 发布时间: 2021-05-24面试侃集合 | LinkedBlockingQueue篇
加载中招聘面试侃结合 | LinkedBlockingQueue篇
招聘者:好啦,聊完后ArrayBlockingQueue,大家然后说说LinkedBlockingQueue吧
Hydra:还简直不给人喘一口气的机遇,LinkedBlockingQueue是一个根据链表的阻塞队列,內部是由连接点Node组成,每一个被添加序列的原素都是会被封裝成下边的Node连接点,而且连接点中有偏向下一个原素的表针:
static class Node<E> {
E item;
Node<E> next;
Node(E x) { item = x; }
}
LinkedBlockingQueue中的重要特性有下边这种:
private final int capacity;//序列容积
private final AtomicInteger count = new AtomicInteger();//序列中原素总数
transient Node<E> head;//头连接点
private transient Node<E> last;//尾连接点
//出队锁
private final ReentrantLock takeLock = new ReentrantLock();
//出队的等候标准目标
private final Condition notEmpty = takeLock.newCondition();
//入队锁
private final ReentrantLock putLock = new ReentrantLock();
//入队的等候标准目标
private final Condition notFull = putLock.newCondition();
构造方法分成特定序列长短和不特定序列长短二种,不特定时序列较大 长短是int的最高值。当然,你如果真存这么多的原素,很有可能会造成内存溢出:
public LinkedBlockingQueue() {
this(Integer.MAX_VALUE);
}
public LinkedBlockingQueue(int capacity) {
if (capacity <= 0) throw new IllegalArgumentException();
this.capacity = capacity;
last = head = new Node<E>(null);
}
也有另一种在复位时就可以将结合做为主要参数传到的构造函数,完成很好了解,仅仅循环系统启用了后边会提到的enqueue入队方式 ,这儿姑且忽略。
在LinkedBlockingQueue中,序列的头连接点head不是存原素的,它的item是null,next偏向的原素才算是真真正正的第一个原素,它也是有2个用以堵塞等候的Condition标准目标。与以前的ArrayBlockingQueue不一样,这儿出队和入队应用了不一样的锁takeLock和putLock。序列的构造是那样的:
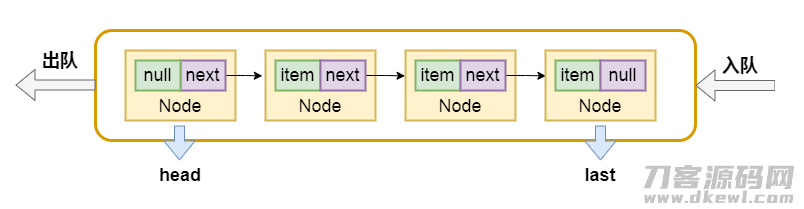
招聘者:为何要应用俩把锁,以前ArrayBlockingQueue应用一把锁,并不是还可以确保进程的安全性么?
Hydra:应用俩把锁,能够 确保原素的插进和删掉并不相互独立,进而可以另外开展,做到提升货运量的的实际效果
招聘者:嗯,那或是规矩,先说插入方法是怎么完成的吧
Hydra:此次也不提父类AbstractQueue的add方式 了,总之它启用的也是派生类的插入方法offer,大家就立即看来offer方式 的源代码:
public boolean offer(E e) {
if (e == null) throw new NullPointerException();
final AtomicInteger count = this.count;//序列中原素数量
if (count.get() == capacity)//已满
return false;
int c = -1;
Node<E> node = new Node<E>(e);
final ReentrantLock putLock = this.putLock;
putLock.lock();
try {
//高并发状况,再度分辨序列是不是已满
if (count.get() < capacity) {
enqueue(node);
//留意这儿获得的是未加上原素前的对列长短
c = count.getAndIncrement();
if (c 1 < capacity)//没满
notFull.signal();
}
} finally {
putLock.unlock();
}
if (c == 0)
signalNotEmpty();
return c >= 0;
}
offer方式 中,最先分辨序列是不是已满,没满状况下将原素封裝成Node目标,试着获得插进锁,在获得锁后会再开展一次序列已满分辨,假如已满则立即释放出来锁。在拥有锁且序列没满的状况下,启用enqueue入队方式 。
enqueue方式 的完成也十分的简易,将当今尾连接点的next表针偏向新连接点,再把last偏向新连接点:
private void enqueue(Node<E> node) {
last = last.next = node;
}
画一张图,便捷你了解:

在进行入队后,分辨序列是不是已满,假如没满则启用notFull.signal(),唤起等候将原素插进序列的进程。
招聘者:我还记得在ArrayBlockingQueue里插进原素后,是启用的notEmpty.signal(),如何这儿还不一样了?
Hydra:说到这,就迫不得已再提一下应用俩把锁来各自操纵插进和获得原素的益处了。在ArrayBlockingQueue中,应用了同一把锁对入队和出队开展操纵,那麼假如在插进原素后再唤起插进进程,那麼很有可能等候获得原素的进程就一直无法得到唤起,导致等待的时间太长。
而在LinkedBlockingQueue中,各自应用了入队锁putLock和出队锁takeLock,插进进程和获得进程是不容易相互独立的。因此 插进进程能够 在这儿持续的唤起别的的插进进程,而不用担忧是不是会使获得进程等待的时间太长,进而在一定水平上提升了货运量。当然,由于offer方式 是是非非堵塞的,并不会挂起来堵塞进程,因此 这儿唤起的是堵塞插进的put方式 的进程。
招聘者:那然后往下看,为何要在c相当于0的状况下能去唤起notEmpty中的等候获得原素的进程?
Hydra:实际上获得原素的方式 和上边插进原素的方式 是一个方式的,只需有一个获得进程在实行方式 ,那麼便会持续的根据notEmpty.signal()唤起别的的获得进程。仅有当c相当于0时,才证实以前序列中早已沒有原素,此刻获得进程才很有可能会被堵塞,在这个时候才必须被唤起。上边的这种可以用一张图来表明:
因为大家以前说过,序列中的head连接点能够 觉得不是储存数据信息的代表性连接点,因此 能够 简易的觉得出队时立即取下第二个连接点,自然这一全过程并不是十分的认真细致,我能在后面解读出队的全过程中再开展补充说明。
招聘者:那麼堵塞方式 put和它有什么不同?
Hydra:put和offer方式 总体构思一致,不一样的是上锁是应用的是可被终断的方法,而且当序列中原素已满时,将进程添加notFull等候序列中开展等候,编码中反映在:
while (count.get() == capacity) {
notFull.await();
}
这一全过程反映在上面那幅图的notFull等候序列中的原素上,也不反复表明了。此外,和put方式 较为相近的,还有一个带上等待的时间主要参数的offer方式 ,能够 开展比较有限時间内的堵塞加上,当请求超时后舍弃插进原素,大家只看和offer方式 不一样一部分的编码:
public boolean offer(E e, long timeout, TimeUnit unit){
...
long nanos = unit.toNanos(timeout);//变换为纳秒
...
while (count.get() == capacity) {
if (nanos <= 0)
return false;
nanos = notFull.awaitNanos(nanos);
}
enqueue(new Node<E>(e));
...
}
awaitNanos方式 在await方式 的基本上,提升了请求超时跳出来的体制,会在循环系统中测算是不是抵达预置的请求超时時间。假如在抵达请求超时時间前被唤起,那麼会回到请求超时時间减掉早已耗费的時间。不论是被别的进程唤起回到,或是抵达特定的请求超时時间回到,只需方式 传参不大于0,那麼就觉得它早已请求超时,最后立即回到false完毕。
招聘者:费这么大顿时间才把插进讲搞清楚,我先喝口水,你然后说获得原素方式
Hydra:……那首先看非堵塞的poll方式
public E poll() {
final AtomicInteger count = this.count;
if (count.get() == 0)//队列入空
return null;
E x = null;
int c = -1;
final ReentrantLock takeLock = this.takeLock;
takeLock.lock();
try {
if (count.get() > 0) {//序列非空
x = dequeue();
//出队前序列很长的队伍
c = count.getAndDecrement();
if (c > 1)
notEmpty.signal();
}
} finally {
takeLock.unlock();
}
if (c == capacity)
signalNotFull();
return x;
}
出队的逻辑性和入队的十分类似,当序列非空时就实行dequeue开展出队实际操作,进行出队后假如序列依然非空,那麼唤起等候序列中挂起来的获得原素的进程。而且当出队前的原素总数相当于序列长短时,在出队后唤起等候序列上的加上进程。
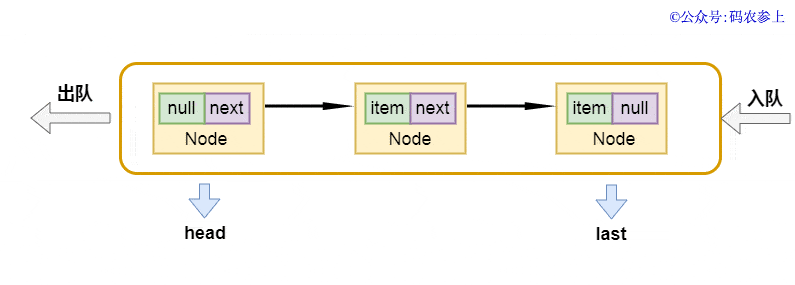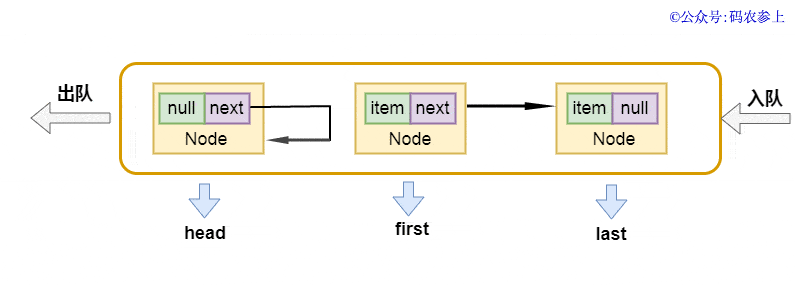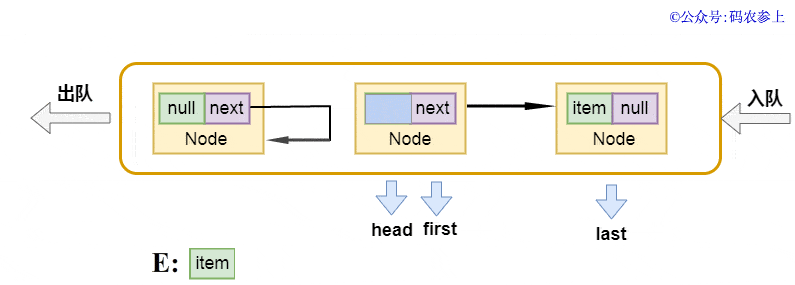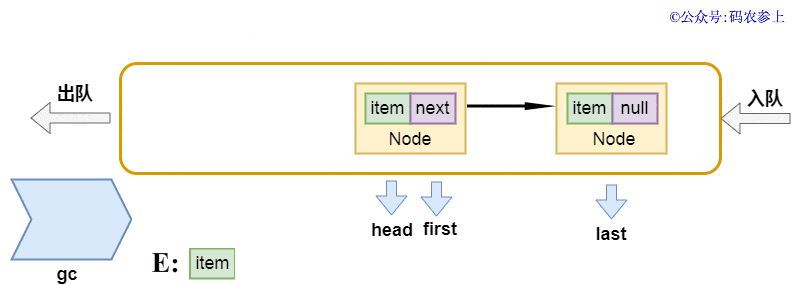
出队方式 dequeue的源代码以下:
private E dequeue() {
Node<E> h = head;
Node<E> first = h.next;
h.next = h; // help GC
head = first;
E x = first.item;
first.item = null;
return x;
}
以前提及过,头连接点head并不储存数据信息,它的下一个连接点才算是真真正正实际意义上的第一个连接点。在出队实际操作中,先获得头连接点的下一个连接点first连接点,将当今头连接点的next表针偏向自身,编码中有一个简易的注解是help gc,本人了解这儿是为了更好地减少gc中的引入记数,便捷它更早被收购 。以后再将新的头连接点偏向first,并回到清除为null前的內容。应用图来表明是那样的:
招聘者:(看一下腕表)take方式 的总体逻辑性也类似,能简易归纳一下吗
Hydra:堵塞方式 take方式 和poll的构思基本一致,是一个能够 被终断的堵塞获得方式 ,在队列入空时,会挂起来当今进程,将它加上到标准目标notEmpty的等候序列中,等候别的进程唤起。
招聘者:再让你一句话的時间,汇总一下它和ArrayBlockingQueue的不同点,我想下班回家了
Hydra:行吧,我汇总一下,有下边几个方面:
- 序列长短不一样,
ArrayBlockingQueue建立时要特定长短而且不能改动,而LinkedBlockingQueue能够 特定还可以不特定长短 - 储存方法不一样,
ArrayBlockingQueue应用二维数组,而LinkedBlockingQueue应用Node连接点的链表 ArrayBlockingQueue应用一把锁来操纵原素的插进和清除,而LinkedBlockingQueue将入队锁和出队锁分离出来,提升了高并发特性ArrayBlockingQueue选用二维数组储存原素,因而在插进和清除全过程中不用转化成附加目标,LinkedBlockingQueue会转化成新的Node连接点,对gc会出现危害
招聘者:明日早上9点,老街坊,大家再聊一聊其他
Hydra:……
假如文章内容对您有一定的协助,热烈欢迎扫码关注 程序员参上









