本文由 发布,转载请注明出处,如有问题请联系我们! 发布时间: 2021-05-26探索专有领域的端到端ASR解决之道
加载中探寻特有行业的端到端ASR对策
引言:文中从《Shallow-Fusion End-to-End Contextual Biasing》下手,探寻处理特有行业的端到端ASR。
文中共享自华为云服务小区《语境偏移如何解决?专有领域端到端ASR之路(一)》,全文创作者:xiaoye0829 。
针对商品级的全自动语音识别技术(Automatic Speech Recognition, ASR),可以融入特有行业的情境偏位(contextual bias),是一个很重要的作用。举个事例,针对手机的ASR,系统软件要能精确鉴别出客户说的app的名称,联络人名字这些,而不是音标发音同样的别的词。更实际一点,例如读作“Yao Ming”的这一词句,在体育文化行业可能是大家众所周知的选手“姚明”,可是在手机上,它可能是大家手机通讯录里边一个称为“姚敏”的盆友。怎样伴随着主要用途的转变,处理这类误差难题便是大家这一系列产品的文章内容要探寻的关键难题。
针对传统式的ASR系统软件,他们通常有单独的声学材料实体模型(AM)、发音词典(PM)、及其语言模型(LM),当必须对特殊行业开展偏位时,能够 根据特殊情境的语言模型LM来偏位鉴别的全过程。可是针对端到端的实体模型,AM、PM、及其LM被融合变成一个神经元网络实体模型。这时,情境偏位针对端到端的实体模型十分具备趣味性,在其中的缘故关键有下列好多个层面:
1. 端到端实体模型只在编解码时采用了文字信息内容,做为比照,传统式的ASR系统软件中的LM能够 应用很多的文字开展训炼。因而,大家发觉端到端的实体模型在鉴别稀缺、情境依靠的英语单词和语句,例如名词短语时,相比于传统式实体模型,更非常容易错误。
2. 端到端的实体模型充分考虑编解码高效率,一般在beam search编解码时的每一步只享有小量的候选词(一般为4到10个词),因而,稀缺的英语单词语句,例如依靠情境的n-gram(n元短语),很有可能没有beam中。
此前的工作中关键是在试着将单独训炼的情境n-gram 语言模型融进到端到端实体模型中,来处理情境模型的难题,这一作法也被称作:Shallow fusion (浅结合)。可是她们的方式针对专业名词解决得较为差,专业名词一般在beam search时就早已被裁剪没了,因而即便 添加语言模型来做偏位,也于事无补,由于这类偏位一般在每一个word转化成后才开展偏位,而beam search在grapheme/wordpiece (针对英语而言,grapheme指的是26个英文英文字母 1空格符 12常见标点符号。针对汉语而言,grapheme指的是3755一级中国汉字 3008二级中国汉字 16标点) 等sub-word模块上开展预测分析。
在这篇博闻中,大家来详细介绍试着处理这个问题的一篇工作中:《Shallow-Fusion End-to-End Contextual Biasing》,这篇工作中是Google发布在InterSpeech 2019上的工作中。在这个工作上,最先,为了更好地防止还没有应用语言模型开展偏位,专业名词就被修枝没了,大家探寻在sub-word模块上开展偏位。次之,大家探寻在beam 修枝前应用contextual FST。第三,由于情境n-gram一般和一组一同作为前缀(“call”, “text”)一起应用,大家也去探寻在shallow fusion时结合这种作为前缀。最终,为了更好地协助专业名词的模型,大家探寻了多种多样技术性去运用规模性的文字数据信息。
大家在这儿,最先详细介绍下Shallow fusion,给出一串视频语音编码序列x=(x_1, …, x_K),端到端的实体模型輸出一串子词级的后验概率遍布y=(y_1,…,y_L),即P(y|x). Shallow fusion的含意便是将端到端的輸出评分与一个外界训炼的语言表达LM评分在beam search时开展结合:
y^{*}=argmax logP(y|x) \lambda P_C(y)y∗=argmaxlogP(y∣x) λPC(y)
在其中\lambdaλ是一个用于调整端到端实体模型和语言模型权重值的主要参数。为了更好地搭建用以端到端实体模型的情境LM,大家假定早已知道一系列的英语单词级参考点语句,并把她们编写出了n-gram的WFST(weighted finite state transducer)。这一英语单词级的WFST,随后被转化成一个做为拼读转化器的FST,这一FST能够 把一串graphemes/wordpieces转化成相匹配的英语单词。
全部以前的偏位工作中,不论是对于传统式方式或是是端到端实体模型,全是将情境LM和底材实体模型(例如端到端实体模型或是ASR声学材料实体模型)的评分在英语单词(word)或是子词(sub-word)网格图上开展融合。端到端的实体模型因为在编解码时,一般设定了较为小的beam阀值,造成了其编解码途径相比于传统式的方式较少。因而文中关键探寻在beam修枝前将情境信息内容运用到端到端实体模型里。
在我们挑选对grapheme开展偏位,一个担忧是大家很有可能会出现很多的多余的词句,与情境FST配对上,进而吞没这一beam。
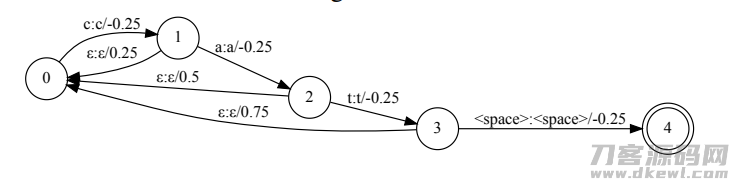
举例说明看来,如上图所述所显示,如果我们想偏位这一英语单词“cat”,那麼情境FST搭建的总体目标便是去偏位“c”“a”和“t”这三个字母。在我们要想往“c”这一英文字母去偏位时,大家很有可能不但会把“cat”添加到beam中,也是有很有可能会把“car”这类不相干的英语单词添加到beam中。可是假如我们都是在wordpiece方面开展偏位,有关的subword有较少的配对,因而,大量有关的英语单词能被添加beam中。或是以“cat”这一事例举例说明,如果我们依照wordpiece来偏位,那麼“car”这个词就不容易进到beam中。因而,在文中中,大家应用了一个4096尺寸的wordpiece词汇。
大家进一步剖析,Shallow fusion改动了輸出的后验概率,因而大家还可以发觉shallow fusion会损害这些沒有词句必须偏位的视频语音,即这些去情境化的视频语音。因而,大家探寻只去偏位这些合乎特殊作为前缀的语句,举例来说,在手机中检索手机联系人时,一般会先说一个“call”或是“message”,或是想音乐播放时,会先说一个“play”。因而在文中中,我们在搭建情境FST时,充分考虑这种作为前缀词句。大家提取出在情境偏位英语单词前发生过50词之上的作为前缀词句。最终,大家得到了292个常见作为前缀词句用以搜索手机联系人,11个用以播放音乐,66个用以搜索app。大家搭建了一个无权重值的作为前缀FST,并把它和情境FST联级起來。大家也容许一个前所未有缀选择项,去绕过这种作为前缀词。
一个提升 专业名词普及率的方式是运用很多的无监管数据信息。无监管的数据信息来源于语音搜索功能中的密名视频语音。这种视频语音运用一个SOTA实体模型开展解决,仅有这些具备高confidence的视频语音会被保存出来。最终,为了更好地确保大家留下的视频语音关键有关专业名词,大家用了一个专业名词标明器(便是ner里的CRF作编码序列标明),并保存含有专业名词的视频语音。运用以上方式,大家获得了一万件无监管的视频语音,并融合了3500万条有监管的视频语音开展训炼,在训炼时,每一个batch内80%的时间有监管的数据信息,20%是无监管的数据信息。运用无监管的数据信息,有一个难题便是她们鉴别出去的文本很有可能有错,鉴别的結果也会限定名字的拼读,例如到底是Eric,或是Erik,或是Erick。因而,大家还可以运用很多的专业名词,融合TTS的方式,造就了一个生成的数据。大家从互联网技术上对于不一样类型去发掘很多的情境偏位词句,例如多媒体系统、社交媒体、及其app等类型。最终,大家提取除开大约58万条联络人名字,4万2万条歌曲名,及其七万个app的名称。下面,大家从日志中去发掘很多的作为前缀词句,例如,“call John mobile”,能够 获得作为前缀词“call”相匹配到社交媒体行业。随后,大家运用特殊类型的作为前缀词和专业名词去转化成语音识别技术的文字,并运用语音合成器,为每一个类型转化成了大概一百万条视频语音。大家进一步为这种视频语音再加上了噪声来仿真模拟房间内的响声。最终,在训炼时,每一个batch内90%的时间有监管的数据信息,10%的是生成的数据信息。
最终,大家探寻了是不是能加上大量的专业名词到有监管的训炼集中化。从总体上,大家对每一条视频语音运用专业名词标明器,寻找在其中的专业名词。针对每一个专业名词,大家得到了其音标发音特点。举例来说,例如“Caitlin”能够 表明成音标发音企业(phonemes)“K eI t l @ n”.随后,大家从发音词典中,寻找有同样音标发音企业编码序列的词句,例如“Kaitlyn”。针对真正的视频语音,和能够 更换的英语单词,我们在训炼时,任意更换。这一作法,能够 让实体模型观查到大量的专业名词。一个更立即的立足点是,实体模型可以在训炼的情况下拼读出大量的名称,那麼在后面编解码时,融合情境FST,更可以拼读出这种名称。
下边看一下试验一部分。全部试验均根据RNN-T实体模型,encoder里包括一个time reduction层,及其8层LSTM,各层有2000个掩藏层模块。decoder包括2层的LSTM,各层有2000个掩藏层模块。encoder和decoer被送至一个协同互联网中,这一互联网有600个掩藏层模块。随后这一协同互联网被送至一个softmax里,輸出为有96个模块的graphemes或是是4096个模块的wordpieces。在逻辑推理时,每条视频语音随着着一系列偏位语句用于搭建一个情境FST。在这个FST中,每条弧(arc)都是有同样的权重值。这一权重值为每一个文件目录(例如歌曲,手机联系人等)的检测集各自调整。
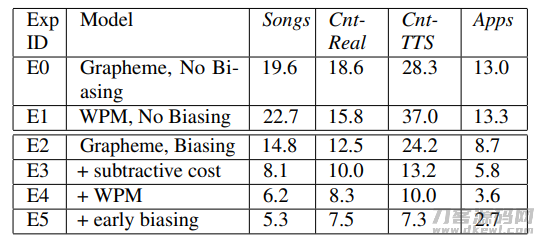
图中是Shallow Fusion的一些結果,E0和E1是grapheme和wordpieces的結果,这种实体模型是沒有开展偏位的。E2是grapheme带偏位的結果,可是没有一切文中中的提高对策。E3是用了一个加减法成本(subtractive cost)去避免在beam中保存槽糕的候选词,这一实际操作在基本上全部的检测集上面产生了提高。再从grapheme方面的偏位变换到wordpiece上的偏位,即我们在更长的模块上开展偏位,有利于在beam内维持有关的候选词,并提升 实体模型的特性。最终,大家的E5实体模型在beam search修枝前,就运用偏位FST,大家称作early biasing,那样有利于保证好的候选词能更早的保存在beam里,并产生了附加的特性提高。总而言之,大家最好是的shallow fusion实体模型是在wordpiece方面开展偏位,并含有subtractive cost和early biasing。
因为情境参考点的很有可能存有于语句中,大家也必须确保当情境偏位不会有时,实体模型的实际效果不容易降低,即不容易危害这些不含有参考点词的视频语音的鉴别。为了更好地检测这一点,我们在VS test数据上开展了试验,大家任意从Cnt-TTS检测集中化挑选了200个参考点语句,去搭建一个参考点FST。下面的图展现了试验的結果: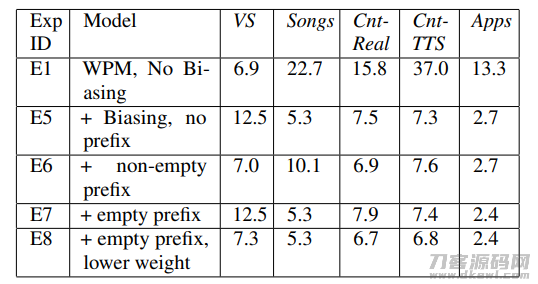
从这一表格中能够 见到,E1是大家的baseline实体模型,当加上偏位后,E5实体模型在VS上发生了许多水平上的实际效果降低。为了更好地处理这个问题,传统式的实体模型在偏位FST中包括了作为前缀词。如果我们只在见到一切非前所未有缀词后,才运用偏位(E6),我们可以观查到VS数据上相较E5发生了結果提高,可是在别的有偏位词的检测集在,发生了結果降低。进一步,在我们容许在其中一条作为前缀能够 为空时(关键想处理有偏位词的情景),可是大家只是得到了与E5相近的結果。为了更好地处理这个问题,大家针对情境语句用了较小的权重值假如前边是一个空的作为前缀词(即沒有作为前缀词)。运用这一方式,大家观查到E8相比于E1实体模型,在VS上获得了不大水平的实际效果降低,可是在有偏位语句的检测集在,可以维持有实际效果提高。
在剖析完后以上內容后,大家进一步探寻下,当实体模型能认知到大量的专业名词时,大家是不是能进一步提高偏位的工作能力。大家的基准线实体模型是E8,这一实体模型是在3500万的有监管数据上训炼获得的。融合大家上边的无监管数据信息和转化成的数据信息,大家干了下边的试验: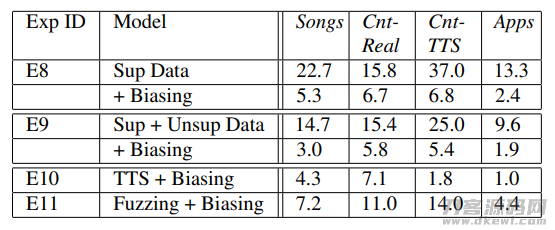
E9的试验結果展现,当有没有监管的数据信息一起训炼时,在每个数据上,都是有实际效果提高。当有转化成的数据信息一起训炼时(E10),对比于E9在TTS检测集上面有更高的实际效果提高,可是在真正情景数据Cnt-Real上发生了很大水平的下降(7.1 vs 5.8),这说明在TTS偏位检测集在的提高,关键来自训练集和检测集间配对的声频自然环境,而不是学得了更丰富的专业名词的词汇。
加关注,第一时间掌握华为云服务新鮮技术性~









