本文由 发布,转载请注明出处,如有问题请联系我们! 发布时间: 2021-05-28Redis学习笔记七:主从集群
加载中Redis学习心得七:主从关系群集
创作者:Grey
全文详细地址:Redis学习心得七:主从关系群集
单机版,单连接点,单案例的Redis会有哪些难题呢?
非常容易造成服务器宕机,那麼如何解决呢?
能够根据主备方法

另外能够完成读写分离
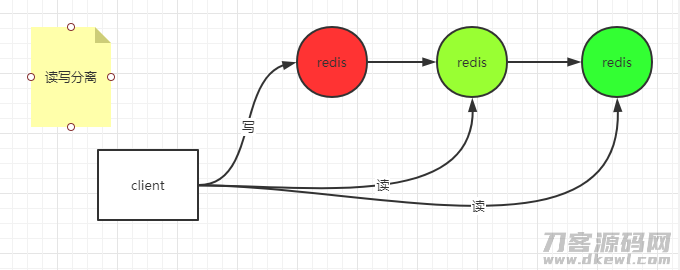
这儿的每一个连接点是全量的,镜像系统的。
单连接点的容积比较有限并且点射的工作压力较为大,如何解决呢?
能够分不一样的案例来存不一样的业务流程数据信息
每一种业务流程数据信息还可以依据不一样的标准放进同一组的Redis库文件
引进好几个Redis案例后,会发生数据信息一致性的难题,如何解决呢?
假如要做到强一致性(同歩方法),就非常容易造成不易用性,例如一个连接点写取得成功后,同歩到别的连接点,假定别的连接点有一个网络延时或是常见故障,便会造成全部服务项目不能用,因此,假如要确保可以用 ,必须忍受遗失一些数据信息(主连接点写取得成功马上给手机客户端回到取得成功,多线程把数据库同步到别的预留连接点)。假如要确保数据不遗失(确保最后一致性),能够考虑到应用消息队列。
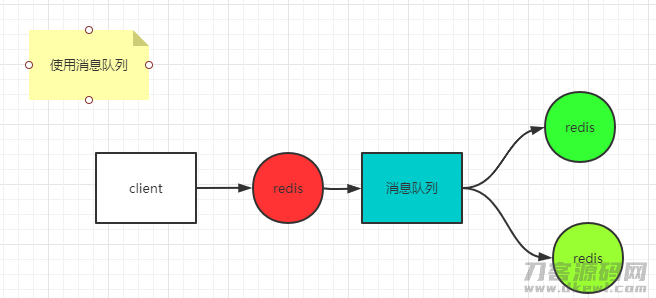
这儿就规定消息队列自身是靠谱的,这类方法确保了最后一致性,也会有什么问题,例如好几个手机客户端浏览的情况下,有可能会得到不一致的数据信息。
主从关系方法
手机客户端能够浏览主,还可以浏览从
主备方法
手机客户端只浏览主,不浏览备,仅有当主挂掉才浏览备
不管主从关系和主备,主都变成服务器宕机,如何解决这个问题呢?
因此务必要对主做HA(例如主挂掉,从机顶上去做服务器)
要对主开展HA,务必要挑选一个高可用性的监管程序流程,
监管程序流程的设计方案要考虑到,是好几个监管程序流程汇报Redis挂掉才算Redis确实挂掉(如果不那样,非常容易造成脑裂难题,即:发生数据信息系统分区)
如果有N个连接点,必须N/2 一个连接点汇报出现异常(一半以上),才算确实出现异常。
脑裂是不是要解决,需看你的系统分区容忍性。
设备的数量是合数比较好。
主从复制试验
根据install_server.sh脚本在一台设备安裝三个redis案例
-
6379
-
6380
-
6381
最先停用这三个案例,随后把这三个案例的环境变量统一放进一个地区,我放到/data文件目录下
cp /etc/redic/*.conf /data/
改动三个案例的以下配备
# 关掉aof
appendonly no
# 设定前台接待运作
daemonize no
# 注解掉logfile
# logfile /var/log/redis_6379.log
随后运行三个案例
redis-server /data/6379.conf
redis-server /data/6380.conf
redis-server /data/6381.conf
运行手机客户端
redis-cli -p 6379
redis-cli -p 6380
redis-cli -p 6381
把6380 和 6381 设定为6379的从机,在6380和638一两个手机客户端均实行
replicaof 127.0.0.1 6379
我们在6379手机客户端实行一条句子
set k1 from6379
随后在6380和6381都实行
127.0.0.1:6381> get k1
"from6379"
127.0.0.1:6380> get k1
"from6379"
能够见到从机同歩到服务器的数据信息
在6380或是6381中随意一台的手机客户端实行
127.0.0.1:6381> set k2 asdfasd
(error) READONLY You can't write against a read only replica.
会提醒以下信息内容:
(error) READONLY You can't write against a read only replica.
即在从机没法做写实际操作。
假定两部从机挂掉一台,挂完之后,服务器还干了许多次的实际操作,这时假如挂掉的从机再次运行(以--appendonly no方式),总是增加量同歩数据信息。
如果是以appendonly yes方法运行挂掉的从机,则会开启全量同歩
rdb方法能够纪录当时跟随者的信息内容,因此能够保证增加量,而aof不容易纪录,因此只有全量。









