本文由 发布,转载请注明出处,如有问题请联系我们! 发布时间: 2021-06-07做个地道的c++程序猿:copy and swap惯用法
加载中做一个正宗的c 程序员:copy and swap常用法
假如你对外国语有兴趣,那毫无疑问听过“idiom”这个词。牛津词典针对它的表述叫惯用语,再精减一些能够 叫“四字成语”。要想把握一门语言表达,在其中的“四字成语”是不得不学的,而期待变成正宗的语言表达使用人,“idiom”则是不可或缺的。编程语言实际上和外国语也很相近,二者都是有自身的英语的语法,一个个涵数也如同一个个语汇,绝大多数的外国语全是自然语言理解,拥有浓厚的历史时间文化内涵,因而有许多idiom,而计算机语言尽管仅有短短的数十岁,idiom却不比前面一种少。但是针对编程设计语言表达的idiom而言相比文化艺术历史时间的累积倒更好像工程项目工作经验具体指导下的最佳实践。
总的来说,我并并不是在强烈推荐你像学外语一样学c ,殊不知想要做个一个正宗的c 程序猿,普遍的idiom是不能不知道的。今日大家就讨论一下copy and swap idiom是怎么一回事儿。
文中数据库索引
- 设计方案一个二维数组
- 还缺些哪些
- rule of zero
- 默认设置只开展浅拷贝
- rule of five
- copy and swap常用法
- 完成自定拷贝
- 假如发生了出现异常
- copy and swap
- 针对挪动取值
- 特性比照
设计方案一个二维数组
前座提醒:不必效仿这一事例,有相近的要求应当找寻第三方库或是应用器皿/智能指针来完成相近的作用。
如今大家设计制作一个二维数组,这一二维数组能够 存随意的数据信息,因此 大家必须泛型;我还想要能在复位时特定二维数组的长短,因此 大家必须一个构造方法来分派动态数组,因此大家的编码第一版是那样的:
template <typename T>
class Matrix {
public:
Matrix(unsigned int _x, unsigned int _y)
: x{_x}, y{_y}
{
data = new T*[y];
for (auto i = 0; i < y; i) {
data[i] = new T[x]{};
}
}
~Matrix() noexcept
{
for (auto i = 0; i < y; i) {
delete [] data[i];
}
delete [] data;
}
private:
unsigned int x = 0;
unsigned int y = 0;
T **data = nullptr;
};
x是横着长高宽比,y是竖向长短,而在c 里要想表明那样的构造恰好得把x和y互换,那样一个x=4, y=3的matrix看起来是下边的实际效果:
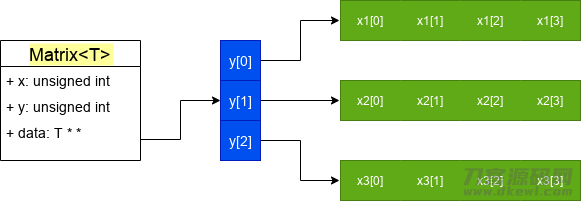
不言而喻,大家的二维数组实际上是好几个独立分派的一维数组组成的,这也代表着她们中间的运行内存很有可能并不是持续的,这也是我不会强烈推荐效仿这类完成的缘故之一。
在构造方法中大家分派了运行内存,而且对二维数组应用了方括号复位器,因此 二维数组内如果是类种类数据信息则会默认设置复位,如果是标量种类(int, long等)则会开展零复位,因而不必担心大家的二维数组里会发生未复位的废弃物值。
然后大家还界定了析构函数用以释放出来資源。
看上去一个简单的二维数组类Matrix界定好啦。
还缺些哪些
对,判断力很有可能对你说是否有没有什么忽略。
判断力一般不是靠谱的,殊不知此次它却十分准,并且大家忽略的物品不仅一个!
但是在查缺补漏以前请允许我对2个早已众人皆知的c 标准炒个冷饭。
rule of zero
c 的类种类里有几种独特友元函数:默认设置构造方法、拷贝构造方法、挪动构造方法、析构函数、拷贝赋值运算符和挪动赋值运算符。
假如客户沒有界定(就算是空涵数体,除非是是=default)这种独特友元函数,且沒有别的英语的语法界定的矛盾(例如界定了一切构造方法都是会造成默认设置构造方法不开展合成),那麼c语言编译器会合成这种独特友元函数并且用在必须他们的地区。
在其中拷贝结构/取值、挪动结构/取值是对于每一项类的非数据格式组员开展拷贝/挪动。析构函数则全自动启用每一项类的非数据格式组员的析构函数(如果有得话)。
看上去是很便捷的作用吧,假如我的类有10个成员函数,那c语言编译器合成这种涵数能够 省掉许多苦恼了。
这就是rule of zero:假如你的类沒有自身界定一切一个除开默认设置构造方法外的独特友元函数,那麼就不应该界定一切一个拷贝/挪动构造方法、拷贝/挪动赋值运算符、析构函数。
标准库的器皿都界定了自身的资源优化配置方式,如果我们的类只应用这种规范杜兰特的內容,或是沒有自身申请办理资源分配(文件句柄,运行内存)等,则应当遵循“rule of zero”,c语言编译器会全自动为大家生成适合的涵数。
默认设置只开展浅拷贝
假如我想在类里分派点資源呢?例如一些系统软件的文件句柄,共享内存哪些的。
那就需要小心了,例如针对大家的Matrix,c语言编译器生成的拷贝赋值运算符是相近那样的:
template <typename T>
class Matrix {
public:
/* ... */
// 生成的拷贝赋值运算符相近下边那样
Matrix& operator=(const Matrix& rhs)
{
x = rhs.x;
y = rhs.y;
data = rhs.data;
}
private:
unsigned int x = 0;
unsigned int y = 0;
T **data = nullptr;
};
难题很显著,data被浅拷贝了。针对表针的拷贝实际操作,默认设置总是拷贝表针自身,而不容易拷贝表针所偏向的运行内存。
殊不知即便 能拷贝表针偏向的运行内存,在大家这一Matrix里或是有什么问题的,由于data偏向的运行内存里存的好多个也是表针,他们各自偏向其他运行内存地区!
那样会有哪些伤害呢?
2个表针偏向同一个地区,并且2个表针最终都是会被析构函数delete,当delete第二个表针的情况下便会造成双向释放出来的bug;假如只删掉在其中一个表针,2个表针偏向的运行内存会无效,对另一个表针偏向的无效运行内存开展浏览可能造成更知名的“释放出来后器重”系统漏洞。
这两大类缺点宛如c er始终没法清醒的噩梦。这也是我不会强烈推荐你效仿这一事例的又一个缘故。
rule of five
假如“rule of zero”不适合,那麼就需要遵照“rule of five”的提议了:假如拷贝类独特友元函数、挪动类独特友元函数、析构函数这五个涵数中界定了随意一个(显式界定,不包括c语言编译器生成和=default),那麼别的的涵数客户也应当显式界定。
拥有自定析构函数因此 必须别的独特友元函数非常好了解,由于自定析构函数一般代表着释放出来了一些类自身申请办理到的資源,因而大家必须别的涵数来管理类专业案例被拷贝/挪动时的个人行为。
而一般挪动类独特友元函数和拷贝类的是互相抵触的。
挪动代表着使用权的迁移,拷贝代表着使用权共享资源或是以当今类复制一个一样的可是彻底单独的新案例,这种针对使用权挪动实体模型而言全是严禁的个人行为,因而一些类只有挪动不可以拷贝,例如mutex和unique_ptr。
而一些物品是适用拷贝的,但挪动的实际意义并不大,例如二维数组或是一块被申请办理的运行内存。
最终一种则另外适用挪动和拷贝,一般拷贝造成团本是更有意义的,而挪动则在一些状况下协助从临时性目标那边提升特性。例如vector。
大家的Matrix正好归属于后面一种,挪动能够 提升特性,而复制团本能够 让同一个二维数组被多种多样优化算法解决。
Matrix自身界定了析构函数,因而依据“rule of five”应当最少完成挪动类或拷贝类独特友元函数中的一种,而大家的类要另外适用二种词义,当然是一个也不可以落下来。
copy and swap常用法
讲了这么多也该进到主题了,篇数比较有限,因此 大家关键看拷贝类涵数的完成。
完成自定拷贝
由于浅拷贝的一系列难题,大家再次完成了恰当的拷贝构造方法和拷贝赋值运算符:
// 一般构造方法
Matrix<T>::Matrix(unsigned int _x, unsigned int _y)
: x{_x}, y{_y}
{
data = new T*[y];
for (auto i = 0; i < y; i) {
data[i] = new T[x]{};
}
}
Matrix<T>::Matrix(const Matrix &obj)
: x{obj.x}, y{obj.y}
{
data = new T*[y];
for (auto i = 0; i < y; i) {
data[i] = new T[x];
for (auto j = 0; j < x; j) {
data[i][j] = obj.data[i][j];
}
}
}
Matrix<T>& Matrix<T>::operator=(const Matrix &rhs)
{
// 检验自取值
if (&rhs == this) {
return *this;
}
// 清除旧資源,分配后拷贝新数据
for (auto i = 0; i < y; i) {
delete [] data[i];
}
delete [] data;
x = rhs.x;
y = rhs.y;
data = new T*[y];
for (auto i = 0; i < y; i) {
data[i] = new T[x];
for (auto j = 0; j < x; j) {
data[i][j] = rhs.data[i][j];
}
}
return *this;
}
那样做恰当,但十分唠叨。例如拷贝构造方法里复位xy和分配内存的工作中事实上和构造方法中的沒有差别,一句俗话叫“Don't repeat yourself”,因此 我们可以依靠c 11的新英语的语法构造方法分享把这一部分工作中授权委托给构造方法,大家的拷贝构造方法只开展二维数组原素的拷贝:
Matrix<T>::Matrix(const Matrix &obj)
: Matrix(obj.x, obj.y)
{
for (auto i = 0; i < y; i) {
for (auto j = 0; j < x; j) {
data[i][j] = obj.data[i][j];
}
}
}
拷贝赋值运算符里也是有和构造方法 析构函数反复的一部分,大家能简单化吗?缺憾的是我们不能在赋值运算符里分享实际操作给构造方法,而delete this后再应用构造方法也是未定义个人行为,由于this代指的类案例要不是new分派的则不合理合法,如果是new分派的也会由于delete后相匹配存储空间已无效再度开展浏览是“释放出来后器重”。那大家先启用析构函数再在同一个存储空间上结构Matrix呢?针对能普普通通析构的种类而言,它是彻底合理合法的,遗憾的是自定析构函数会让类没法“普普通通析构”,因此 大家也不可以那么做。
虽然不可以简单化编码,但大家的类并不是也可以恰当工作中了没有,先发布再说吧。
假如发生了出现异常
看上去Matrix能够 一切正常运作了,殊不知发布几日后程序流程崩溃了,由于拷贝赋值运算符的new句子或者一次二维数组原素复制抛出去了一个出现异常。
你要那样哪些了不起的,我早已防患于未然了:
try {
Matrix<T> a{10, 10};
Matrix<T> b{20, 20};
// 一些实际操作
a = b;
} catch (exception &err) {
// 打些log,随后对a和b做些善后处理
}
这一段编码无懈可击的表面下却暗藏杀机:a在拷贝不成功后原始记录早已删掉,而新数据也很有可能只复位了一半,它是浏览a的数据信息会造成多种多样未定义个人行为,在其中一部分会让崩溃。
重点在于怎么让出现异常产生的情况下a和b都能维持合理情况,如今我们可以确保b合理,必须保证的是怎样确保a能返回复位情况或是更强的方法——让a维持取值前的情况不会改变。
对于为何不许取值计算不抛出现异常,由于大家无法控制客户存进的T种类的案例是否会抛出现异常,因此 不可以开展操纵。
copy and swap
如今大家不但没处理反复编码的难题,大家的赋值运算符基本上把析构函数和拷贝构造方法抄了一遍;还引进了新的难题取值计算的出现异常安全系数——要不取值取得成功,要不别对计算的操作数造成一切危害。
该轮到“copy and swap常用法”隆重登场了,它能够 帮大家一次处理这两个难题。
大家讨论一下它有哪些窍门:
- 最先大家用拷贝构造方法从rhs复制一个tmp,这一步重复使用了拷贝构造方法;
- 然后用一个确保不容易产生不正确的swap涵数互换tmp和this的成员函数;
- 涵数回到,互换后的tmp消毁,相当于重复使用了析构函数,旧資源也获得了恰当清除。
假如拷贝产生不正确,那麼前边事例里的a不容易被更改;假如tmp析构产生不正确,自然它是不太可能的,由于大家早已把析构函数申明成noexcept了,还需要抛出现异常只有表明程序流程碰到了十分比较严重的不正确会被系统软件马上中断运作。
显而易见,关键是swap涵数,大家看一下是怎么完成的:
template <typename T>
class Matrix {
friend void swap(Matrix &a, Matrix &b) noexcept
{
using std::swap; // 这一步容许c语言编译器根据ADL找寻适合的swap涵数
swap(a.x, b.x);
swap(a.y, b.y);
swap(a.data, b.data);
}
};
根据ADL,我们可以运用std::swap或者一些种类对于swap完成的提升版本号,而noexcept则确保了大家的swap不容易抛出异常(简易的互换一般都根据挪动词义完成,一般保证不容易造成出现异常)。实质上swap的逻辑性是很简单明了的。
拥有swap帮助,如今大家的赋值运算符能够 那么写了:
Matrix<T>& Matrix<T>::operator=(const Matrix &rhs)
{
// 检验自取值
if (&rhs == this) {
return *this;
}
Matrix tmp = rhs; // copy
swap(tmp, *this); // swap
return *this;
}
你乃至还能够省掉自取值检验,由于如今应用了copy and swap后自取值除开消耗了点特性外早已没害了。
应用“copy and swap常用法”不但解决了编码重复使用,还确保了取值实际操作的安全系数,真真正正的一箭双雕。
针对挪动取值
挪动取值计算自身仅仅释放出来左操作数的数据信息,再挪动一些早已得到的資源随后把rhs重设会安全性的复位情况,这种一般都不容易造成出现异常,编码也非常简单沒有过多反复,只不过是释放出来数据信息和把数据信息从rhs挪动到lhs,这两个实际操作是否有点儿熟悉?
对,swap写出去便是为了更好地干这类活干的,因此 大家还能完成move and swap:
Matrix<T>& Matrix<T>::operator=(Matrix2 &&rhs) noexcept
{
Matrix2 tmp{std::forward<Matrix2>(rhs)};
swap(*this, tmp);
return *this;
}
自然,如同我讲的,一般没必要那么写。
特性比照
如今大家的Matrix早已能够 健硕地控制自己申请办理的运行内存資源了。
殊不知也有最终一点疑惑:我们知道copy and swap会多建立一个临时性目标并空出一次互换实际操作,这对特性会产生多少的危害呢?
我只有说会出现一点危害,但这一“一点”究竟多少钱不跑检测因为我空口无凭。所以我根据Google benchmark写了个简易检测,假如还不掌握benchmark如何使用,能够 看看我写的实例教程。
所有的测试程序有200行,确实是太长了,因此 我将它贴在了gist上,你能在这儿查询。
下边是在我的设备上的检测結果:
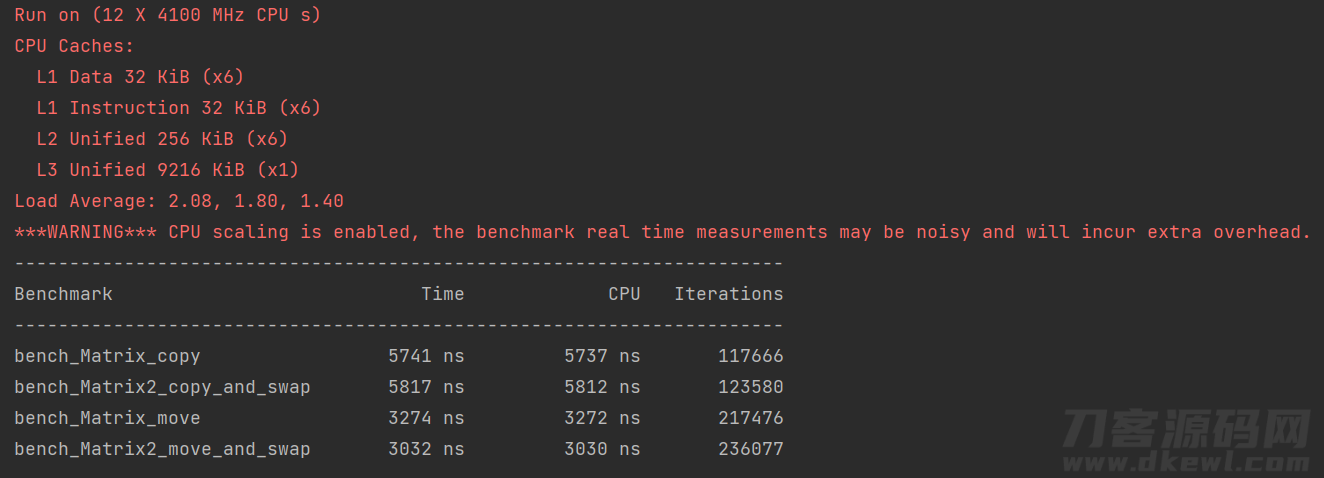
能够 见到特性差别基本上能够 忽略,由于Matrix仅有三个简易的成员函数,当然也不会有很大的花销。
因此 我们建议是:能上copy and swap的地区尽可能上,除非是你检测表明copy and swap产生了比较严重的特性短板。
参照
https://stackoverflow.com/questions/3279543/what-is-the-copy-and-swap-idiom
https://stackoverflow.com/questions/6687388/why-do-some-people-use-swap-for-move-assignments
https://stackoverflow.com/questions/32234623/using-swap-to-implement-move-assignment
http://www.vollmann.ch/en/blog/implementing-move-assignment-variations-in-c .html
https://cpppatterns.com/patterns/copy-and-swap.html









