本文由 发布,转载请注明出处,如有问题请联系我们! 发布时间: 2021-06-16Redis 入门权威指北
加载中Redis 新手入门权威性指北
序言
看一下业务流程碰到了什么问题?
我们要从互联网技术构架的演化之途逐渐谈起Redis的今生前世。
在大家小的时候,网络时代仿佛便是仅有根据肥屁股台式电脑才可以进到一样,那时的手机上仅仅用于打通电话,发发信息,网络购物都还没在我国普及化,Jack Ma 的TB都还没走入家家户户,能上网的客户仅仅非常少的一部分群体。那时的情景是登陆着QQ,玩着单机版的手机游戏,连视频在线收看都并不是那麼顺畅。网络项目的构架是多么的简易:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-b0wLvxoP-1623849610589)(D:\Source\image\Redis\web初始架构.png)]](https://img-blog.csdnimg.cn/20210616212127220.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl8zODg5NzM2NA==,size_16,color_FFFFFF,t_70)
网址前期
那时的互联网项目特性:网站流量低,大部分全是以静态页面为主导,非常少有动态性互动运用,单独数据库查询就可以符合要求。
网址中后期
伴随着互联网技术快速的普及化,很多的客户逐渐应用互联网技术,智能终端愈来愈多的新手入门,总流量逐渐大幅度提升。绝大多数应用MySQL构架的网址在数据库查询上面逐渐发生特性难题,Web程序流程不可以再只是潜心在作用上,与此同时也在追求完美特性。逐渐应用缓存文件技术性减轻数据库查询工作压力,提升数据库查询的构造和数据库索引。一开始时较为时兴的是根据文档缓存文件来减轻数据库查询工作压力,可是当浏览量再次扩大,文档缓存文件中的数据信息不可以在几台Web服务端中间共享资源,很多的小文档IO也产生了较为高的IO工作压力。在这类状况下,Memcache就变成一款十分合理的解决方法。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9nreu5z7-1623849610591)(D:\Source\image\Redis\MemCache缓存.png)]](https://img-blog.csdnimg.cn/20210616212144999.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl8zODg5NzM2NA==,size_16,color_FFFFFF,t_70)
Memcache做为一个单独的分布式缓存网络服务器,为好几个Web服务端给予了一个共享资源的性能卓越缓存文件服务项目,在Memcache网络服务器上,又发展趋势了依据hash优化算法来开展几台Memcache缓存文件服务项目的拓展,随后又发生了一致性hash来处理提升或降低cdn加速造成 重新hash产生的很多缓存文件无效难题。
网址中后期
因为数据库查询的载入工作压力提升,Memcached只有减轻数据库查询的载入工作压力。读写能力集中化在一个数据库查询上让数据库查询承受不住,绝大多数网址逐渐应用主从复制技术性来做到读写分离,以提升 读写能力特性和读库的扩展性。Mysql的master-slave方式变成这个时候的网址标准配置了:

网址再中后期
在Memcached的高速缓存,MySQL的主从复制,读写分离的基本以上,这时候MySQL主库的写工作压力逐渐发生短板,而信息量的不断激增,因为MyISAM应用表锁,在分布式系统下能发生比较严重的锁难题,很多的分布式系统MySQL运用逐渐应用InnoDB模块替代MyISAM。
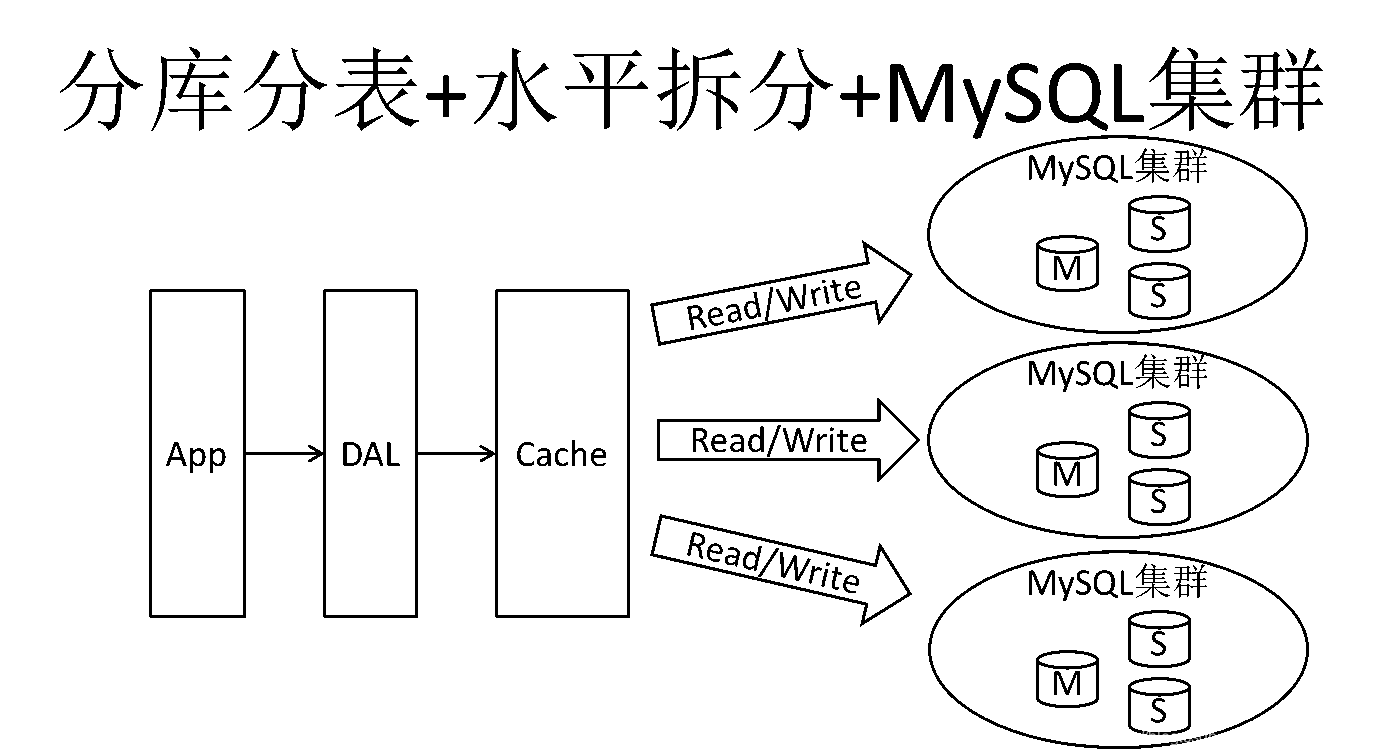
与此同时,逐渐时兴应用数据透析表储备库来减轻写工作压力和数据信息提高的拓展难题。这个时候,数据透析表储备库变成一个受欢迎技术性,是业内探讨的受欢迎技术性难题。也就在这个时候,MySQL发布了还不太平稳的表系统分区,这也给技术水平一般的企业产生了期待。尽管MySQL发布了MySQL Cluster群集,但特性也不可以非常好达到互联网技术的规定,仅仅在可靠性高上给予了十分大的确保。
MySQL数据库查询也常常储存一些大文字字段名,造成 数据库表十分的大,在做数据库备份的情况下就造成 十分的慢,不易迅速修复数据库查询。例如1000万4k高清B尺寸的文字就贴近40GB的尺寸,假如可以把这种数据信息从MySQL省掉,MySQL将越来越十分的小。关系型数据库很强劲,可是它并不可以非常好的适应全部的应用领域。MySQL的扩展性差(必须繁杂的技术性来完成),互联网大数据下IO压力太大,表结构变更艰难,恰好是当今应用MySQL的开发者遭遇的难题。
目前大概构架
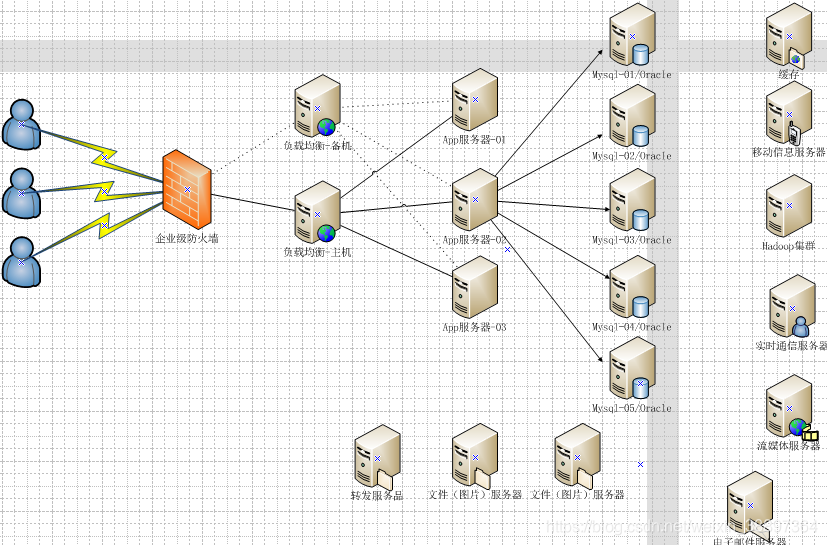
伴随着数据获取终端设备愈来愈多,及其大量的迅速的服务器带宽,信息内容不仅是以前的业务流程数据信息,随着着数据信息多元化的互联网时代,网络时代下怎样提高:高可扩、性能卓越、分布式系统变成持续必须提高和攻破的难题。数据信息的规模大幅度提升、数据信息款式(不符合于之前的报表型,如文字、照片、声频、视頻,各种终端设备这些)和数据信息实用性的规定(例如直播间、金融基金。。。。)。怎样在每个控制模块中间提高数据储存和查找高效率也越来越至关重要。
当传统式的关联型数据库查询针对一些半结构型、非非结构化数据的解决主要表现欠佳的情况下,怎样储存解决这种非非结构化数据,逐渐拥有新的思索和解决对策。
NoSQL解决方法
直至说白了NoSQL的解决方法面世了,NoSQL是为“为新起的新数据储存空间取名”难题而造就的一个专有名词。Not only SQL。其观念不给予SQL查看数据信息的方式,只给予一些非常简单的、类似API插口的方法来数据存储结构。自然,也会出现一些专用工具为NoSQL数据储存给予了SQL语言表达的通道。
ACP 定律
一个分布式架构只有与此同时完成一致性、易用性和系统分区容错性中的2个。比如:Vogels(amazon技术总监 Werner Vogels)提及的很有实际象征性的一句话:
“在一系列科学研究結果中发觉,在大型的分布式架构中,因为互联网隔开,一致性与易用性不可以与此同时达到。代表着三个因素数最多只有与此同时完成2个,不太可能三者兼具;放开一致性的规定会提高系统软件的易用性,提高一致性代表着系统软件必须放弃一定的易用性。”

NoSQL优点:
-
易拓展
- NoSQL数据库种类多种多样,但他们都是有一个相通的特性:便是除去关联型数据库查询的“关联型”特性。数据信息中间无关联,那样就越来越很容易拓展,而相对性应的看来:关联型数据库查询改动表结构十分艰难。这就为新项目架构模式给予了更高的拓展室内空间。
-
大信息量性能卓越
-
NoSQL数据库查询都具备十分高的读写能力特性,特别是在在大信息量的状况下,主要表现一样出色。这归功于NoSQL数据库查询中数据中间沒有“关联”,数据库查询构造简易。
-
从缓存文件视角看来,MySQL的Query Cache是表等级的细粒度缓存文件,假定储存了100条数据信息,在其中有一条数据信息改动了,全部缓存文件无效,高效率很低。而NoSQL数据库查询的缓存文件是纪录级的粗粒度缓存文件,一切一条纪录的改动也不危害别的纪录,高效率很高。
-
-
多种多样灵便的数据库系统
- NoSQL数据库查询不用事前为要储存的数据信息创建字段名,随时随地能够储存自定的数据类型。而在关系型数据库里,删改字段名是一件十分不便的事儿。如果是十分大信息量的表,调整改动字段名真是便是一个恶梦。
Redis
1. 介绍:
Redis:Remote Dictionary Server(远程控制词典网络服务器): 是用C语言开发设计根据运行内存彻底开源系统完全免费的,遵循 BSD 协议书性能卓越的key-value 分布式存储,是混合开发的非关联型数据库查询。
适用各种类型的算法设计,如 字符串数组(strings), 散列(hashes), 目录(lists), 结合(sets), 井然有序结合(sorted sets) 与范畴查看, bitmaps, hyperloglogs 和 自然地理室内空间(geospatial) 数据库索引半经查看。 Redis 内嵌了 拷贝(replication),LUA脚本制作(Lua scripting), LRU推动事情(LRU eviction),事务管理(transactions) 和不一样等级的 硬盘分布式锁(persistence), 并根据 Redis卫兵(Sentinel)和全自动 系统分区(Cluster)给予可扩展性(high availability)。
之上表明来源于官方网站
梳理一下其特点:
- 1.适用多种多样算法设计(就是指Value的种类,Key的种类只有是String):
- String:字符串数组
- Hashes:hach,类似Map<String ,String>,且其KV值只有是String种类
- list:目录,能够反复的结合且井然有序,井然有序既能够根据数据库索引开展实际操作
- sets:结合,不能反复的结合,混乱
- ZSets:井然有序结合,sorted sets,根据特定score值开展排列的结合
- 适用数据信息分布式锁,能够将运行内存中的数据信息储存在硬盘中,重启的情况下根据配备开展载入应用
- Redis 适用数据信息的备份数据,即 master-slave 方式的备份数据。
Redis的优点
-
1)特性极高 – Redis 可以读的速率是 110000 次/s,写的速率是 81000 次/s 。
-
2)丰富多彩的基本数据类型 – Redis 适用二进制实例的 Strings, Lists, Hashes, Sets 及Ordered Sets 基本数据类型实际操作。
-
3)分子 – Redis 的全部实际操作全是原子性的,含意便是要不取得成功实行要不不成功彻底不实行。单独实际操作是原子性的。好几个实际操作也适用事务管理,即原子性,根据 MULTI 和 EXEC命令包起來。
-
4)丰富多彩的特点 – Redis 还适用 publish/subscribe, 通告, key 到期这些特点。
Redis 与别的 key-value 储存有哪些不一样?
-
1.Redis 拥有 更加繁杂的算法设计而且给予对她们的原子性实际操作,这是一个有别于别的数据库查询的演变途径。Redis 的基本数据类型全是根据基本上算法设计的与此同时对程序猿全透明,不用开展附加的抽象性。
-
2.Redis 运作在运行内存中可是能够分布式锁到硬盘,因此在对不一样数据开展快速读写能力时必须衡量运行内存,由于信息量不可以超过硬件配置运行内存。在内存数据库层面的另一个优势是,对比在硬盘上同样的繁杂的算法设计,在运行内存中实际操作起來比较简单,那样 Redis能够做许多 內部多元性较强的事儿。与此同时,在磁盘格式层面她们是紧密的以增加的方法造成的,由于她们并不一定开展任意浏览。
Redis的应用领域
- 网络热点数据信息加快查看(关键情景),如网络热点产品、热点信息等浏览量较高的数据信息
- 及时记录查询,如公交车到站信息内容、线上总数信息内容等
- 及时性信息内容操纵,如短信验证码操纵、网络投票操纵等
- 分布式系统信息共享,如分布式系统群集构架中的session分离出来消息队列
2.Redis的安裝
-
但凡技术性必登其官方网站,在官方网站下载redis-xx.xx.xx.tar.gz安装文件并上传入Linux的/opt文件目录;
-
在/opt文件目录下,解压安装包到特定的根目录下:指令:tar -zxvf redis-xx.xx.xx.tar.gz
-
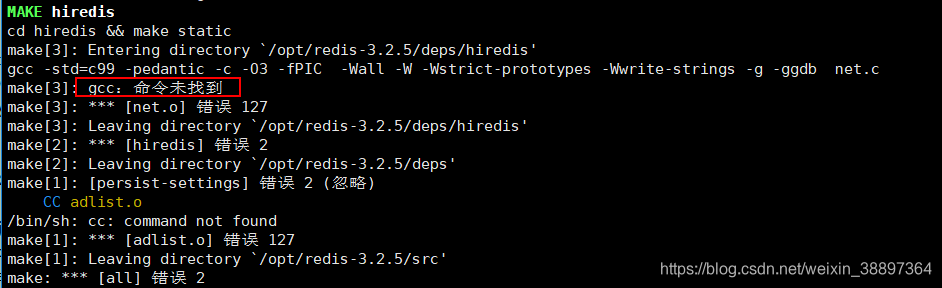
安装gcc自然环境,大家必须将源代码编译程序后再安裝,因而必须安裝c语言的编译程序自然环境!不可以立即make!我们可以先检验是不是有gcc自然环境:

若沒有gcc立即make会出错:
安装gcc:sudo yum install -y gcc-c
应用sudo管理权限安裝。假如在沒有安装gcc自然环境下,假如实行了make,不容易取得成功!安裝自然环境后,
第二次make有可能出错:Jemalloc/jemalloc.h:沒有那一个文档
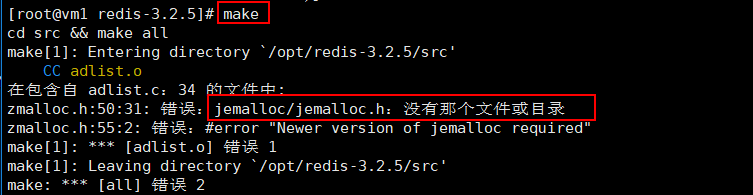
**解决方法:运作make distclean** 随后再开展make编译程序
-
编译程序,实行make指令!
-
编译程序进行后,安裝,实行make install命令!
-
默认设置文档会被安裝到 /usr/local/bin文件目录
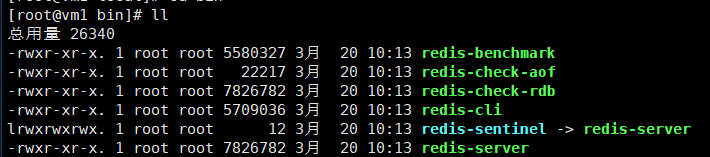
| bin文件目录下文件目录 | 文档功效 |
|---|---|
| Redis-benchmark | 稳定性测试。规范是每秒钟80000次写实际操作,110000次读实际操作 (服务项目运行起來后实行,相近安兔兔跑分) |
| Redis-check-aof | 修补有什么问题的AOF文档 |
| Redis-check-dump | 修补有什么问题的dump.rdb文件 |
| Redis-sentinel | 运行卫兵,群集应用 |
| redis-server | 运行网络服务器 |
| redis-cli | 运行手机客户端 |
Redis相对应的shell指令的实际操作能够参照菜鸟教程https://www.runoob.com/redis/redis-install.html
3.Redis环境变量
redis环境变量为redis安裝的bin文件目录下redis.conf文档
1.企业配备
# 1k => 1000 bytes
# 1kb => 1024 bytes
# 1米 => 1000000 bytes
# 1mb => 1024*1024 bytes
# 1g => 1000000000 bytes
# 1gb => 1024*1024*1024 bytes
1k和1kb是不一样的,企业的英文大小写不比较敏感
2.include主要参数
能够将公共性的配备放进到一个公共性的环境变量中,随后根据子环境变量引进父环境变量中的內容!
将配备依照控制模块分离!一般将引入公共性配备的文档表明放到配备最前面:redis 服务项目运行必须特定相匹配的环境变量,默认设置是bin下的redis.conf文档。
################################## INCLUDES ###################################
# If instead you are interested in using includes to override configuration
# options, it is better to use include as the last line.
#
# include /path/to/local.conf
# include /path/to/other.conf
3.Network参数配置
| 特性 | 含意 | 备注名称 |
|---|---|---|
| bind | 限制浏览的主机地址 | 要是没有bind,便是随意ip详细地址都能够浏览。工作环境下,必须写自身网站服务器的ip详细地址。 |
| protected-mode | 安全防范方式 | 要是没有特定bind命令,都没有配备登陆密码,那麼安全模式就打开,只容许该设备浏览(loaclhost或127.0.0.1)。 |
| port | 端口 | 默认设置是6379 |
| tcp-backlog | 数据连接全过程中,某类情况的序列的长短 | redis是并行处理的,特定分布式系统时浏览时排长队的长短。超出后,就展现阻塞状态。能够理解是一个要求抵达后至到接纳过程解决前的序列长短。(一般状况下是运维管理依据群集特性管控)分布式系统状况下,此值能够适度调高。 |
| timeout | 请求超时時间 | 默认设置绝不请求超时 |
| tcp-keepalive | 对手机客户端的心跳检测时间间隔 |
4.general参数配置
| 特性 | 含意 | 备注名称 |
|---|---|---|
| daemonize | 是不是为xinetd方式运作 | xinetd方式能够在后台程序 |
| pidfile | 过程id文档储存的途径 | 配备PID文件路径,当redis做为xinetd运作的情况下,它会把 pid 默认设置写到 /var/redis/run/redis_6379.pid 文档里边 |
| loglevel | 界定日志等级 | debug(纪录很多日志信息内容,适用开发设计、产品测试) verbose(较多日志信息内容) notice(适当日志信息内容,应用于工作环境) warning(仅有一部分关键、重要信息内容才会被纪录) |
| logfile | 日志文档的部位 | 当特定为空字符串时,为规范輸出,假如redis以xinetd方式运作,那麼日志可能輸出到/dev/null |
| syslog-enabled | 是不是纪录到系统软件日志 | 要想把日志纪录到系统软件日志服务项目中,就把它改为 yes |
| syslog-ident | 设定系统软件日志的ID | |
| syslog-facility | 特定系统软件日志设定 | 务必是 USER 或是是 LOCAL0-LOCAL7 中间的值 |
| databases | 设定数据库查询总数 | 默认设置16,数据库索引为0-15,根据select num 开展挑选 |
5.别的
| 特性 | 含意 | 备注名称 |
|---|---|---|
| requirepass | 密码设置 | |
| maxclients | 最大连接数 | |
| maxmemory | 较大占有是多少运行内存 | 一旦占有运行内存超限额,就逐渐依据缓存清理对策清除数据信息假如Redis没法依据清除标准来清除运行内存中的数据信息,或是设定了“不允许清除”, 那麼Redis则会对于这些必须申请办理运行内存的命令回到错误报告,例如SET、LPUSH等。 |
| maxmemory-policy noeviction | 缓存清理对策 | (1)volatile-lru:应用LRU优化算法清除key,只对设定了到期時间的键 (2)allkeys-lru:应用LRU优化算法清除key (3)volatile-random:在到期结合中清除任意的key,只对设定了到期時间的键 (4)allkeys-random:清除任意的key (5)volatile-ttl:清除这些TTL值最少的key,即这些近期要到期的key (6)noeviction:不开展清除。对于写实际操作,仅仅回到错误报告 |
| maxmemory-samples | 样本量 | 样本量越小,准确度越低,可是特性越好。 LRU优化算法和最少TTL优化算法都并不是是精准的优化算法,只是估计值, 因此你能设定样版的尺寸。一般设定3到7的数据。 |
4.分布式锁
Redis是怎么开展分布式锁的?Redis数据信息都是在运行内存中,运行内存自身就并不是一个分布式锁机器设备,一关闭电源或是重新启动不就木拥有嘛?
怎样防止这个问题或是尽量减少内容丢失。
我们在开场的情况下详细介绍redis的情况下也讲到redis是适用分布式锁,因此,redis给予了不一样等级的分布式锁方法:
- RDB分布式锁方法可以在特定的间隔时间对数据信息开展快照更新储存;
- AOF分布式锁方法纪录每一次对网络服务器写的实际操作,当服务器重启的情况下会再次实行这种指令来修复初始的数据信息,AOF指令以append-only方式增加储存每一次写的实际操作到文件结尾。Redis还能对AOF文档开展后台管理调用,促使AOF文档的容积不会过大。
- 假如只期待数据信息在网络服务器运作的情况下存有,还可以不选用一切分布式锁方法
- 还可以与此同时打开二种分布式锁方法。在这里状况下,当redis重新启动的情况下会优先选择加载AOF文档来修复初始的数据信息。由于一般 状况下AOF文档储存的数据要比RDB文档储存的数据要详细;
之上的分布式锁等级仅仅二种分布式锁方法的组成。那大家如今就各自看一下这二种分布式锁方法的实际完成。
4.1.RDB分布式锁方法
4.1.1RDB介绍:
在特定的间隔时间内将运行内存中的数据快照更新载入硬盘,也就是行语讲的Snapshot快照更新,它修复时是将快照更新文档立即读到运行内存里。
4.1.2 工作方案
每过一段时间,就把运行内存中的数据信息储存到电脑硬盘上的特定文档中。
RDB是默认设置打开的!
4.1.3 RDB特性
Redis会独立建立(fork)一个子过程来开展分布式锁,会先将数据信息载入到一个临时文件夹中,待分布式锁全过程都告一段落,再用这一临时文件夹更换之前分布式锁好的文档。全部全过程中,主过程不是开展一切IO实际操作的,这就保证了非常高的特性假如必须开展规模性数据信息的修复,且针对数据修复的一致性并不是十分比较敏感,那RDB方法要比AOF方法更为的高效率。
最后一次分布式锁后的数据信息很有可能遗失。
例如:2次储存的间隔时间内,宕机,或是产生关闭电源难题。
4.1.4 RDB储存对策和开启体制
储存对策
-
save 900 1 900 秒内假如最少有 1 个 key 的值转变,则储存
-
save 300 10 300 秒内假如最少有 10 个 key 的值转变,则储存
-
save 60 10000 60 秒内假如最少有 10000 个 key 的值转变,则储存
-
save “” 便是禁止使用RDB方式(一般无需该方式,默认设置打开上面三个)
RDB开启体制
-
①根据全自动储存的对策,便是达到储存对策标准
-
②实行save,或是bgsave指令!实行时,是阻塞状态。
-
③实行flushall指令,也会造成dump.rdb,但里边是空的,没有意义。
-
④当实行shutdown指令时,也会积极地备份数据数据信息。
4.1.5 RDB优点和缺点
优势:
- RDB是一个十分紧密的文档,它储存了某一时间点的数据,十分适用数据的备份数据。例如你能在每一个钟头储存一下以往24小时内的数据信息,与此同时每日储存以往30天的数据信息,那样即便出了难题还可以依据要求修复到不一样版本号的数据
- RDB 是一个紧密的单一文档,很便捷传输到另一个远侧数据信息中,特别适合用以灾祸修复
- RDB在储存RDB文档时,父过程fork出一个子过程。下面的工作中所有由子过程来做,父过程不用做别的IO实际操作,因此RDB分布式锁方法能够利润最大化redis的特性
- 与AOF方法对比,再回应大的数据的情况下,RDB方法会迅速一些
缺陷
- 假如redis出现意外停止工作的状况下遗失数据信息至少得话,RDB方法不符合当今要求。尽管我们可以配备不一样的save 时间点(比如每过五分钟而且数据有一百个写的实际操作)时,Redis要详细的储存全部数据是一个较为繁杂的工作中,一般 在save间距正中间产生redis服务项目奔溃重新启动,会遗失这一save间距中的数据信息
- RDB必须常常fork子过程来储存数据到电脑硬盘上,当数据较为大的情况下,fork全过程是十分用时的,很有可能会造成 Redis在一些ms级内不可以回应手机客户端的要求。假如数据极大且CPU特性欠佳的状况下,延迟时间会做到秒级。
4.2 AOF分布式锁方法
4.2.1 AOF介绍
AOF是以日志的方式来纪录每一个写实际操作,将每一次对数据信息开展改动,都把新创建、改动数据信息的指令储存到特定文档中。Redis重启时载入这一文档,再次实行新创建、改动数据信息的指令恢复数据库。
默认设置不打开,必须手动式打开
AOF文档的储存途径,同RDB的途径一致。
AOF在储存指令的情况下,总是储存对数据信息有改动的指令,也就是写实际操作!
当RDB和AOF存的不一致的状况下,依照AOF来修复。由于AOF是对RDB的填补。备份数据周期时间更短,也就更靠谱。
4.2.2 AOF 储存对策
-
appendfsync always:每一次造成一条新的改动数据信息的指令都实行储存实际操作;高效率低,可是安全性!
-
appendfsync everysec:每秒钟实行一次储存实际操作。假如在未储存当今秒内实际操作时发生了关闭电源,依然会造成 一部分内容丢失(即一秒钟的数据信息)。
-
appendfsync no:从来不储存,将数据信息交到电脑操作系统来解决。更快,也更不安全的挑选。
强烈推荐(而且也是默认设置)的对策为每秒钟 fsync 一次, 这类 fsync 对策能够兼具速率和安全系数。
4.2.3 AOF文件损坏修复
假如AOF文档中发生了残留指令,会造成 网络服务器没法重新启动。这时必须依靠redis-check-aof专用工具来修补!
redis-check-aof --fix 文档
4.2.4 AOF的优点和缺点
优势
- 应用AOF会让Redis更为耐久度:能够应用不一样的fsync对策,默认设置应用每秒钟fsync 的对策,Redis的特性仍然非常好,一旦发生常见故障,数最多遗失一秒的数据信息
- AOF文档是一个只开展增加的日志文档,因此不用载入seek,即便因为一些缘故(储存空间不够,写全过程服务器宕机等)未实行详细的载入指令,还可以应用redis-check-aof专用工具修补这种难题
- Redis 能够在AOF文档容积越来越过大时,全自动的在后台管理对AOF开展调用:调用的新AOF文件包含了修复当今数据需要的最少指令结合。全部调用实际操作是肯定安全性的,由于Redis在建立新AOF文档的全过程中,会再次将指令增加到目前的AOF文档里边,即便调用全过程中产生服务器宕机,目前的AOF文档也不会遗失。而一旦新AOF文件创建结束,Redis便会从旧AOF文档转换到新的AOF文档,并逐渐对新AOF文档开展增加实际操作
- AOF文档井然有序地储存了对数据信息实行的全部载入实际操作,这种载入实际操作以Redis协议书的文件格式储存,因而AOF文档的很容易令人了解,对文档开展剖析(parse)也很轻轻松松。导出来AOF文档也比较简单。举个事例:假如一不小心实行了flushall指令,只需AOF文档未被调用,那麼只需终止网络服务器,清除AOF文档结尾的FLUSHALL指令,并重新启动Redis,就可以修复数据到FLUSHALL实行前的情况。
缺陷
- 针对同样的数据而言,AOF文档的容积一般 超过RDB文档的容积。
- 依据应用的fsync对策,AOF的速率很有可能会慢于RDB。一般状况下,每秒钟fsync的高效率早已很高,而fsync能够让AOF速率和RDB一样快,即便在长时间负荷下也是这般。但是解决极大的载入加载时,RDB能够给予更有确保的较大时间延迟。
- 每一次读写能力都同歩的情况下,有一定的特性工作压力
4.3 如何选择?
小朋友才做挑选,要学好全都要,你独立用RDB你能遗失许多 数据信息,你独立用AOF,你数据修复没RDB来的快,真出什么问题的情况下第一时间用RDB修复,随后AOF做数据补齐,好香!冷备热备一起上,才算是网络时代一个高可扩展性系统软件的关键。
Redis做为内存数据库从实质上而言,假如不愿放弃特性,就不太可能保证数据信息的“肯定”安全性。
RDB和AOF都仅仅尽量在兼具特性的前提条件下减少内容丢失的风险性,假如确实产生内容丢失难题,尽量减少损害。
在全部新项目的构架管理体系中,Redis绝大多数状况是饰演“二级缓存”人物角色。二级缓存合适储存的数据信息
-
常常要查看,非常少被改动的数据信息。
-
并不是十分关键,容许发生有时候的高并发难题。
-
不容易被别的运用程序修改。
假如Redis是做为cdn加速,那麼表明数据信息在MySQL那样的传统式关联型数据库查询中是有宣布版本号的。数据信息最后以MySQL中的为标准。
5. 事务管理
5.1 redis中事务管理介绍
-
Redis中事务管理,有别于传统式的关联型数据库查询中的事务管理。
-
Redis中的事务管理指的是一个独立的防护实际操作。
-
Redis的事务管理中的全部指令都是会实例化、按序地实行且不容易被别的手机客户端推送来的指令要求所切断。
-
Redis事务管理的关键功效是串连好几个指令避免其他指令排队
5.2 redis事务管理常用命令(shell)
| MULTI | 标识一个事务管理块的逐渐 |
|---|---|
| EXEC | 实行事务管理中全部在排长队等候的命令并将连接情况修复到一切正常 当应用WATCH 时,仅有当被监控的键沒有被改动, 且容许查验设置体制时,EXEC会强制执行 |
| DISCARD | 更新一个事务管理中全部在排长队等候的命令,而且将联接情况修复到一切正常。 假如已应用WATCH,DISCARD将释放出来全部被WATCH的key。 |
| WATCH | 标识全部特定的key 被监控起來,在事务管理中有标准的实行(乐观锁) |
5.3 Redis事务管理演试
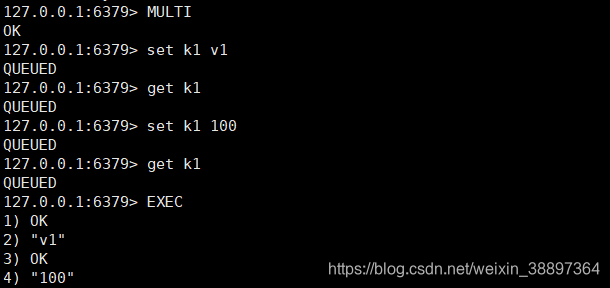
5.3.1 简易联机
MULTI打开联机,EXEC先后实行序列中的指令。
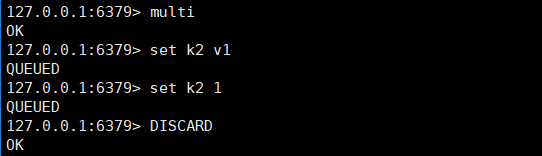
DISCARD半途撤销联机
5.3.2 联机不成功
”殃及池鱼“
在编译程序的全过程中,Redis检验出来不正确的英语的语法指令,因而它觉得这条联机,一定会产生不正确,因而全体人员撤销
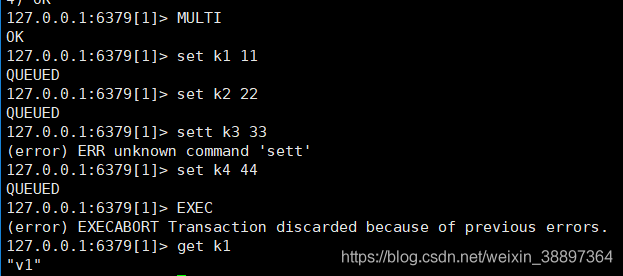
”咎由自取“
此类状况,英语的语法符合要求,Redis仅有在实行中,才能够出现未知错误。而在Redis中,并沒有回退体制,因而不正确的指令,没法实行,恰当的指令会所有实行!
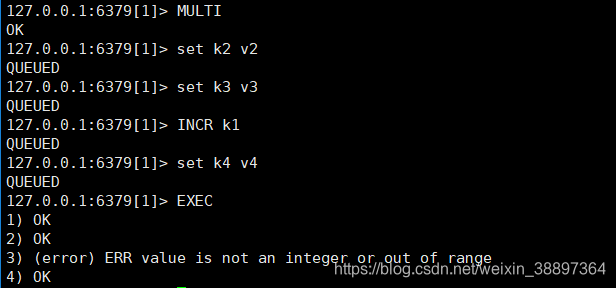
为何Redis不兼容回退
假如应用关联型数据信息如MySQL、SQL Server、Oracle等,事务管理不兼容回退会感觉有点儿意想不到,有点儿怪异。
引入官方网的表明:
- redis指令总是由于不正确的英语的语法而不成功(而且这种难题在入队是不可以发觉),或者指令用在了不正确种类的键上边,换句话说,不成功的指令是由编译程序不正确导致的,而这种不正确应当在开发设计的全过程中被发觉,而不是在生产制造中。含意就:死丫头的,给了你英语的语法如何使用,你要用不对,就自身担负自身填错的成本费。
- redis不用对回退开展解决,就可以让Redis內部维持简易迅速。
5.4redis 锁及对策
Redis不兼容悲观锁。Redis做为cdn加速应用时,以读实际操作为主导,非常少写实际操作,相对应的实际操作被切断的概率较少。不选用悲观锁是为了更好地避免减少特性。
对策
-
Redis选用了乐观锁对策(根据watch实际操作)。乐观锁适用读实际操作,适用多读少写的状况!
-
在事务管理中,能够根据watch指令来上锁;应用 UNWATCH能够撤销上锁;
-
假如在事务管理以前,实行了WATCH(上锁),那麼实行EXEC 指令或 DISCARD 指令后,锁对全自动释放出来,即不用再实行 UNWATCH 了
6.主从复制
6.1 什么叫Redis主从复制
当单机版Redis的特性是比较有限的,而Redis常见其读分布式系统的特点,当一台Redis有要读又要写的情况下,这就顶不住了啊。太过度榨取便会奔溃的哦。那么就把读写分离,又由于读的要求是超过写的实际操作高并发,就可以用一个master设备去写,别的好几个salve设备去进行读的每日任务要求。不但完成了redis储存的扩充,还完成了水准扩充。
配备几台Redis网络服务器,以服务器和备用机的真实身份分离。服务器数据信息升级后,依据配备和对策,自动同步到备用机的master/salver体制,Master以写为主导,Slave以读为主导,二者之间自动同步数据信息。
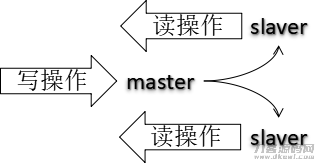
主从关系目地:
-
读写分离提升 Redis特性;
-
防止服务器宕机,容灾备份迅速修复
体制基本原理:
每一次从机中国联通后,都是会给服务器推送sync命令,服务器马上开展存盘实际操作,推送RDB文档到从机,从机接到RDB文档后,开展整盘载入。以后每一次服务器的写系统命令,都是会马上发给从机,从机实行同样的指令来确保主从关系的数据信息一致!
留意:主库接受到SYNC的指令的时候会实行RDB全过程,即便在环境变量中禁止使用RDB分布式锁也会转化成,可是假如主库所属的网络服务器硬盘IO特性较弱,那麼这一拷贝全过程便会发生短板,幸运的是,Redis在2.8.18版本号逐渐完成了无硬盘拷贝作用(但是该作用或是处在实验环节),设定repl-diskless-sync yes。即Redis在与从数据库查询开展拷贝复位时将不容易将快照更新储存到硬盘,只是立即根据互联网发给从数据库查询,防止了IO特性差难题。
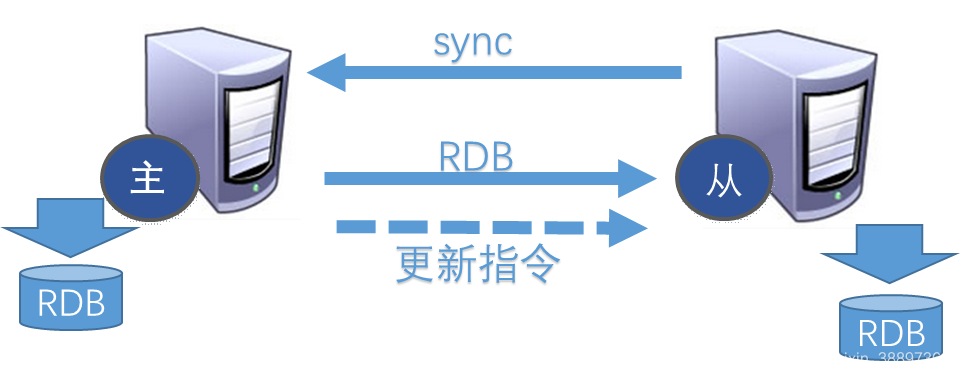
6.2 配备redis主从复制
6.2.1 提前准备
不一样的主机配置不一样的Redis服务项目,不然在一台设备上边跑好几个Redis服务项目,必须配备好几个Redis环境变量。
- ①提前准备Redis环境变量,每一个环境变量,必须配备下列特性
daemonize yes: 服务项目在后台程序
port:端口
pidfile:pid储存文档
logfile:日志文档(要是没有特定得话,就不用)
dump.rdb: RDB
appendonly 关闭,或是是变更appendonly文档的名字。
- ②依据环境变量,运行好几个Redis服务项目
6.2.2 配备
标准:配从配不上主
一、临时性创建从属关系
- 在从服务器上实行SLAVEOF ip:port指令;
- 实行info replication指令
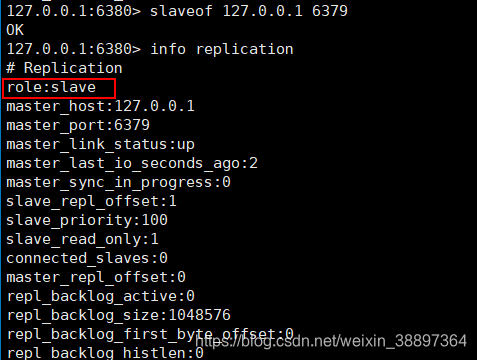
二 永久性创建
在从连接点环境变量中,撰写slaveof特性配备
# slaveof <masterip> <masterport>
三 修复真实身份
指令:slaveof no one
7.哨兵模式
7.1 介绍
在主从复制下,只有一个master,那master假如挂掉,全部redis就不可以确保可以用了。假如某一个slave连接点崩溃了,一样我们不能在分派相匹配的要求到该连接点开展读实际操作。怎样监管主从关系情况,并处理master服务器宕机难题?哨兵模式运用为之。
功效:
-
群集监管:主从关系情况检验
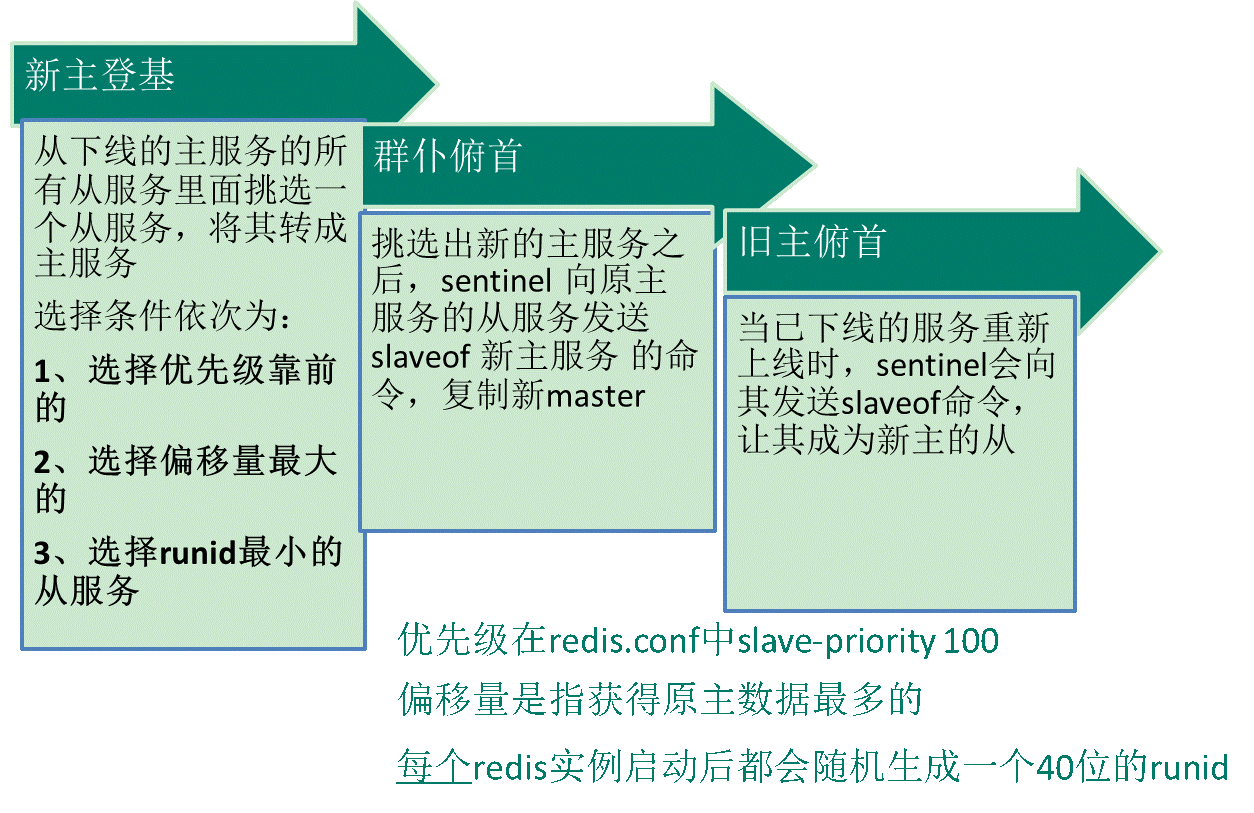
-
常见故障迁移:假如Master出现异常,则会开展Master-Slave转换,将在其中一个Slave做为Master,将以前的Master做为Slave(假如重新启动取得成功 )
-
消息通知:假如某一 Redis 案例有常见故障,那麼卫兵承担推送信息做为警报通告给管理人员。
-
配置中心:假如常见故障迁移发生了,通告 client 手机客户端新的 master 详细地址。
卫兵务必用三个案例去确保自身的可扩展性的,卫兵 主从关系并不可以确保数据不遗失,可是能够确保群集的高可用性
好几个卫兵,不但与此同时监管主从关系情况,且卫兵中间也相互之间监管!
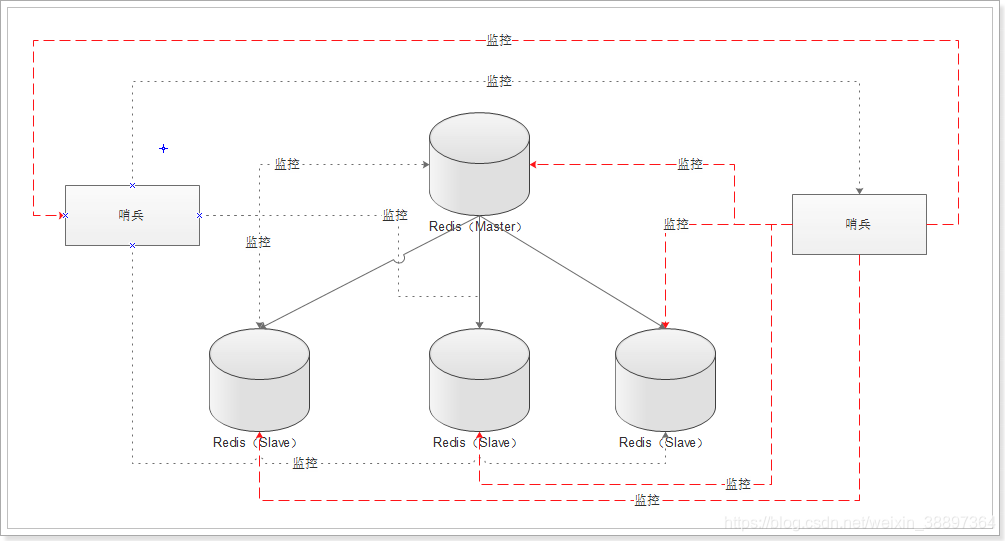
退出:
①主观性退出:Subjectively Down,通称 SDOWN,指的是当今 Sentinel 案例对某一redis网络服务器作出的退出分辨。
②客观性退出:Objectively Down, 通称 ODOWN,指的是好几个 Sentinel 案例在对Master Server作出 SDOWN 分辨,而且根据 SENTINEL is-master-down-by-addr 指令相互之间沟通交流以后,得到的Master Server退出分辨,随后打开failover.
原理:
-
①每一个Sentinel以每秒一次的頻率向它孰知的Master,Slave及其别的 Sentinel 案例推送一个 PING 指令 ;
-
②假如一个案例(instance)间距最后一次合理回应 PING 指令的時间超出 down-after-milliseconds 选择项所特定的值, 则这一案例会被 Sentinel 标识为主观性退出;
-
③假如一个Master被标识为主观性退出,则已经监控这一Master的全部 Sentinel 要以每秒钟一次的頻率确定Master确实进入了主观性退出情况;
-
④当有充足总数的 Sentinel(高于或等于环境变量特定的值)在特定的时间段内确定Master确实进入了主观性退出情况, 则Master会被标识为客观性退出 ;
-
⑤在一般状况下, 每一个 Sentinel 会以每 10 秒一次的頻率向它已经知道的全部Master,Slave推送 INFO 指令
-
⑥当Master被 Sentinel 标识为客观性退出时,Sentinel 往下线的 Master 的全部 Slave 推送 INFO 指令的頻率会从 10 秒一次改成每秒钟一次 ;
-
⑦若沒有充足总数的 Sentinel 愿意 Master 早已退出, Master 的主观性退出情况便会被清除;
-
若 Master 再次向 Sentinel 的 PING 指令回到合理回应, Master 的客观性退出情况便会被清除
汇总
好啦,今日的文章内容就结束了,大家从互联网技术的构架演化看来每个部件服务项目的要求,进而引出来了NoSQL。Redis做为当今cdn加速的弄潮人,大家从Redis的官方网站详细介绍剖析了redis的特性,也得出了Redis安裝的实例及其大家一般关心的配备主要参数的功效。然后从Redis的分布式锁了解了RDB分布式锁方法特性及其其优点和缺点、AOF分布式锁原理 与优点和缺点。然后针对Redis的主从复制及其事务管理了解了Redis的高可用性,了解了哨兵模式的情况和体制。一部分实际操作文章内容沒有列举,由于感觉官方网站早已很详细了,此外菜鸟教程网站针对指令也算详细就沒有反复列举。提议大伙儿手动式在Linux自然环境下安裝redis,眼过千篇比不上手敲一遍。
我是轻风,期待本文对您有协助,害怕真知无限,进一寸有一寸的开心。奥利给。









