本文由 发布,转载请注明出处,如有问题请联系我们! 发布时间: 2021-07-24Redis中一个String类型引发的惨案
加载中 以前见到那么一个实例,有一个精英团队必须 开发设计一个照片分布式存储,规定这一系统软件能迅速纪录照片ID和照片存储目标ID,与此同时还必须 可以依据照片的ID迅速寻找照片存储目标ID。大家假定用10十位数来表明照片ID和照片存储目标ID,比如照片的ID为1101021043,它所相匹配的照片存储目标的ID为2301010051,能够 见到照片ID和照片存储ID恰好是一一对应的,是典型性的key-value方式,因此最先会想起立即应用String种类来储存数据信息。把照片ID和照片存储ID各自做为键值对的key和value来储存。可是伴随着储存的信息量越来越大,Redis的运行内存的需求量也迅速升高,結果碰到了大运行内存Redis案例由于转化成RDB而回应减缓的难题。很显而易见String种类并并不是一种好的挑选,
那有什么办法能够 减少运行内存耗费吗?
String种类的算法设计
最先大家得先掌握为何String储存数据信息时需耗费的存储空间很大。在刚刚的实例中,因为照片ID和照片存储目标ID都是10十位数,大家可以用2个8字节的Long种类来表明这两个ID。因此一组照片ID以及储存目标ID的纪录,具体只必须 16字节就可以了。可是根据对Redis运行内存剖析,一组照片ID以及储存目标ID却占有了64字节,那为何String种类用到64字节呢。实际上 ,除开要纪录具体的数据信息,String种类还必须 附加的存储空间来纪录数据信息的长短、室内空间应用信息内容等,这种信息内容也称为数据库。当具体储存的数据信息较钟头,数据库的室内空间花销就显的较为变大。大家先看来一下String种类是如何保存数据信息的。如果你储存64位有标记的整数金额时,String种类会把它储存为一个8字节的Long种类整数金额,这类储存方法一般 也称为int编码方法。可是,如果你储存的数据信息中包括标识符时,String种类便会用简易动态性字符串数组建筑结构(SDS)来储存。如下图所显示:

-
len:4个字节数,表明buf的占用长短。
-
alloc:4个字节数,表明buf分派的长短,一般超过len。
-
buf:字节数二维数组,储存具体数据信息。为了更好地表明二维数组的末尾,Redis会全自动在二维数组最终加上一个”\0"。
能够 见到,在SDS建筑结构中,除开有储存具体数据信息的buf,也有len和alloc的附加数据库的花销。此外针对String种类而言,除开SDS的附加花销外,还有一个称为RedisObject建筑结构的花销。由于Redis的基本数据类型有很多,不一样的基本数据类型都是有同样的数据库要纪录(比如最后一次浏览時间),因此Redis会选用一个称为RedisObject建筑结构来统一纪录这种数据库。一个RedisObject包括了一个8字节的数据库和一个8字节的表针,这一表针偏向实际数据信息所属,比如String种类的SDS建筑结构所属的基址。如下图所显示:

为了更好地节约存储空间,Redis对Long种类整数金额和SDS的运行内存合理布局干了专业的设计方案。一方面,当储存的是 Long 种类整数金额时,RedisObject 中的表针就立即取值为整数金额数据信息了,那样就无需附加的表针再偏向整数金额了,节约了表针的室内空间花销。另一方面,当储存的是字符串数组数据信息,而且字符串数组不大于 44 字节数时,RedisObject 中的数据库、表针和 SDS 是一块持续的运行内存地区,那样就可以防止运行内存残片。这类合理布局方法也被称作 embstr 编码方法。当字符串数组超过44字节时,SDS的信息量就逐渐变多了,Redis 就不会再把SDS 和
RedisObject 合理布局在一起了,只是会给 SDS 分派单独的室内空间,并且用表针偏向 SDS 构造。这类合理布局方法被称作 raw 编号方式。如下图所显示:

如今大家来测算一下一对照片ID和照片存储目标ID的运行内存的需求量。因为10十位数的照片ID和照片存储目标ID是Long种类整数金额,因此能够 立即用int编号的RedisObject储存。相对性应的RedisObject数据库一部分占8字节,表针一部分被立即取值为8字节的整数金额了。这时,每一个ID会应用16字节,加起來一共是32字节。可是,此外的 32 字节数去哪了呢?
因为Redis是应用全局性哈希表来储存全部的键值对,哈希表的每一项是一个dictEntity的建筑结构来偏向一个键值对。dictEntity由三个8字节的表针构成,各自来偏向key、value及其下一个dictEntity。如下图所显示。

因为Redis应用的内存分配库为jemalloc,jemalloc在释放内存时,会依据申请办理的字节N,找一个比N大的,最贴近N的2的幂频次做为分派的室内空间。
因此申请办理一个24字节的dictEntity,具体会分派3两个字节数。
到现阶段部位,你应该懂了为何String种类来存图ID和照片存储目标ID会占有64个字节数了。一个合理信息内容只有16个字节数,在应用String种类储存时,却要占有64个字节数存储空间,有4八个字节数用于储存元数据信息了,这是否巨大的消耗了存储空间。那麼是否有更为节约运行内存的方式呢?
用缩小目录节约运行内存
Redis里有一种称为缩小目录的构造,十分节约运行内存。大家先回望一下缩小目录的组成。表头有三个字段zlbytes、zllen和zltail,各自表明目录的长短、目录尾的偏移及其目录中entry的数量。缩小目录表尾有一个zlend,表明目录完毕。如下图所显示。
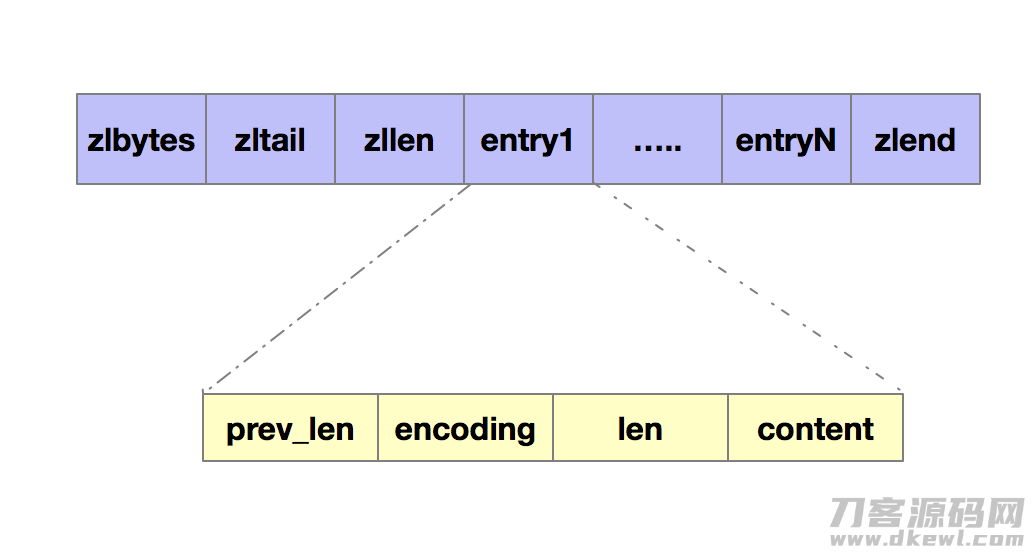
因为缩小目录选用一系列的entry储存数据信息,这种entry会挨个儿置放在运行内存中,不用再用附加的表针开展联接,那样就可以节约表针所占有的室内空间。每一个entry由下列几一部分构成。
-
pre_len:表明前一个entry的长短。prev_len有二种选值状况:1 字节数或 5 字节数。当上一个 entry 长短低于 254 字节数时,prev_len 选值为 1 字节数,不然,就选值为 5 字节数。
-
len:表明本身的长短,占4个字节数。
-
encoding:表明编码方法,占一个字节数。
-
content:储存具体数据信息。
假定大家应用entry来储存照片存储目标ID(占八个字节数),这时,每一个entry的prev_len占有一个字节数就可以了,由于每一个entry的前一个entry的长短低于264字节。这样一来,一个照片目标ID所占有的内存空间是14(1 4 1 8)个字节数,事实上会分派16个字节数。
Redis里根据缩小目录完成了List、Hash和Sorted Set结合种类,那样做的较大 益处便是节约了dictEntity的运行内存花销。针对String种类而言,一个键值对就有一个dictEntity,占有3两个字节数。针对结合种类而言,一个key相匹配了许多数据信息,却仅仅占有了一个dictEntity,那样就节约了存储空间。
怎样用结合种类储存单值的键值对的数据信息
在储存单值键值对的数据信息时,我们可以应用根据Hash种类的二级编码方法。这儿常说的二级编号,就是指把单值的数据信息分解成两一部分,前一部分做为Hash的key,后一部分做为Hash的value。 以照片的ID为1101021043,它所相匹配的照片存储目标的ID为2301010051为例子,大家将照片的ID的前7位(1101021)做为Hash种类的键,后3位(043)和照片存储目标ID为2301010051做为Hash种类的key和value。大家依照这类设计方案,在Redis中插进一条纪录,只占有了16字节,因此和应用String种类占有64字节比照,节约了许多室内空间。 最终,大家再思索一个难题,为何要把照片ID的前7位做为Hash种类的键,后3位做为Hash种类的key呢。我们在Redis存储结构里详细介绍过Redis的Hash种类的二种最底层完成构造,分别是缩小目录和哈希表。Hash 种类设定了用缩小目录储存数据信息时的2个阀值,一旦超出了阀值,Hash 种类便会用哈希表来储存数据信息了。这两个阀值各自相匹配下列2个配备项:
-
hash-max-ziplist-entries:表明用缩小目录储存时hach结合中的较大 原素数量。
-
hash-max-ziplist-value:表明用缩小目录储存时hach结合中单独原素的较大 长短。
在运行内存节约室内空间层面,哈希表就沒有缩小目录那麼高效率。大家仅用后3位做为Hash种类的key,也就确保hach结合中原素的数量不容易超出1000,与此同时大家根据设定hash-max-ziplist-entries=1000,来保证Hash种类最底层应用的是缩小目录这类算法设计。
好啦,今日的详细介绍就到这儿。大量顶势专业知识,请关心公序员师兄 。










