本文由 发布,转载请注明出处,如有问题请联系我们! 发布时间: 2021-08-26[源码解析] 深度学习流水线并行GPipe (2) ----- 梯度累积
加载中[源代码分析] 深度神经网络生产流水线并行处理GPipe (2) ----- 梯度方向积累
[源代码分析] 深度神经网络生产流水线并行处理GPipe (2) ----- 梯度方向积累
5.1 优化器
5.2 包裝器
5.3 运用
3.1 全自动积累
3.2 编码实例
3.3 DistributedDataParallel 的梯度方向积累
3.3.1 单卡实体模型梯度方向总计
3.3.2 DDP怎样加快
3.3.3 no_sync完成
2.1 情况专业知识
2.2 造成缘故
2.3 实质
2.4 VS 数据信息并行处理
2.5 解决困难
1.1 前文回望
0x00 引言
0x01 简述
0x02 基本要素
0x03 PyTorch 梯度方向积累
0x04 Tensorflow完成
0x05 Gpipe完成
0xFF 参照
0x00 引言
梯度方向积累是一种扩大训炼时 batch size的技术性,在当地应用 micro-batch 数次开展正方向和反向传播累积梯度方向后,再开展梯度方向通信规约和优化器升级,这也是用于分摊通讯成本费的一种常见对策。文中根据好多个架构/库的完成比照,让各位对这一技术性有进一步的掌握。
本系列产品别的文章内容以下:
[源代码分析] 深度神经网络生产流水线并行处理Gpipe(1)---生产流水线基本上完成
0x01 简述
1.1 前文回望
前文提及,现阶段分布式系统实体模型训炼几个必需并行处理技术性:
水流并行处理,尤其是怎样全自动设置水流;
梯度方向累积(Gradient Accumulation);
后向重测算;
1F1B 对策(大家将选用PipeDream剖析);
在前原文中,大家详细介绍了Gpipe怎样执行生产流水线并行处理技术性。文中大家详细介绍梯度方向累积(Gradient Accumulation)。
0x02 基本要素
梯度方向积累是一种用于分摊通讯成本费的一种常见对策。它在当地应用 micro-batch 数次开展正方向和反向传播累积梯度方向后,再开展梯度方向通信规约和优化器升级,等同于增加了N倍的batch size。
2.1 情况专业知识
深度神经网络实体模型由很多互相连接的层构成,样版在那些层中开展散播,实际散播包括2个全过程:前向(forward)全过程与反方向(backword)全过程。
前向全过程是以键入测算获得輸出。样版在每一步都根据前向散播开展散播,在根据全部层散播后,互联网为样版转化成预测分析,随后估算每一个样品的损害值,损害值代表着 “针对这一样版,本互联网不对是多少?”。
随后便是反方向全过程。神经元网络在这里全过程中测算这种损害值相对性于实体模型主要参数的梯度方向。能够 觉得着便是一个梯度方向积累的全过程。
最终,这种梯度方向用以测算每个实体模型主要参数的升级。
训炼中,每一个样品的高低由超参数batch size特定,此参数的高低会对最后的建模实际效果发生非常大的危害。一定标准下,batch size设定的越大,实体模型便会越平稳。
2.2 造成缘故
累积梯度方向说白了便是累积后的梯度方向值。为何要累积呢?由于运作存储空间不足用。
在训炼实体模型时,假如一次性将全部训炼数据信息导入到实体模型,常常会导致内存不够,此刻就必须把一个大 Batch 拆分为许多小批号数据信息(专业名词为mini-batch)。分为小批号后,产生一个难题,那便是原本应该是全部信息所有送进后测算梯度方向再升级主要参数,如今变成每一个小批号都需要测算梯度方向升级主要参数,为了更好地不那么经常测算梯度方向,因此就引进了累积梯度方向。换句话说:
将全部dataset分为好几个batch;
各自将每一个batch分为好几个小批号,将每一个小批号来养神经元网络;
每一个小批号尽管测算梯度方向,可是在每一次反向传播后,先不开展优化器的迭代更新。
历经多个小批号后(即一个batch中的全部小批号),用每一个小批号测算的梯度方向的积累和去开展优化器迭代更新主要参数、梯度方向清零的实际操作。
那样就跟把所有数据信息一次性送进实体模型完成训炼实际效果一样了。
2.3 实质
梯度方向累积实质上便是累积 accumulation_steps 个 batch_size/accumulation_steps 的梯度方向, 再依据累积的梯度方向来升级互联网主要参数,以实现真正梯度方向相近batch_size 的实际效果。在运用时,必须 留意合理的扩张学习率。
换句话说:
最先将全部dataset分为好几个batch,每一个 batch size = 32,且假设
accumulation steps = 8;由于
batch size = 32,太大,单机版独立显卡没法跑,因此我们在前向散播的情况下以batch_size = 32 / 8 = 4来估算梯度方向;那样就再各自将每一个batch分为好几个batch size 为 4 的小批号,将每一个小批号逐一来养神经元网络;
每一个小批号尽管测算梯度方向,可是在每一次反向传播(在反向传播的情况下,会将mean_loss也除于8)后,先不开展优化器的迭代更新。
历经
accumulation steps个小批号后(即一个batch中的全部小批号),用每一个小批号测算梯度方向的积累和去开展优化器迭代更新主要参数。最终开展梯度方向清零的实际操作。
解决下一个batch。
那样就跟把 32 batch size 一次性送进实体模型完成训炼实际效果一样了。
实际以下,时间线是由左自右:
------------------- | GLOBAL BATCH -------------------------- ------------------- | | | <--------------------------------------------------------------------------------- | | | -------------- -------------- -------------- -------------- --> | MINI BATCH 0 ----> MINI BATCH 1 ----> MINI BATCH 2 ----> MINI BATCH 3 | ----- -------- ------- ------ ------ ------- ------- ------ | | | | | | | | | | | | v v v v ---- ----- ----- ----- ----- ----- ---- ----- | grad 0 | | grad 1 | | grad 2 | | grad 3 | ---- ----- ----- ----- ----- ----- ---- ----- | | | | | | | | | | | | v v v v ------ ---------------------- ------------------- --------------------- ------ | | | GLOBAL BATCHGRADIENTS | | | ------------------------------------------------------------------------------ ------------------------------------------------------------------------------------> Time
2.4 VS 数据信息并行处理
micro-batch 跟数据信息并行处理有高宽比的相似度:
数据信息并行处理是区域上的,数据信息被拆分为好几个 tensor,与此同时来养好几个机器设备并行处理,随后将梯度方向累加在一起升级。
micro-batch 是時间上的数据信息并行处理,数据信息被拆分为好几个 tensor,这种 tensor 依照时钟频率先后进到同一个机器设备串行通信测算,随后将梯度方向累加在一起升级。
当总的 batch size 一致,且数据信息并行处理的并行度和 micro-batch 的累积频次相同时,数据信息并行处理和 Gradient Accumulation 在统计学上彻底等额的。
Gradient Accumulation 根据好几个 micro-batch的梯度方向累积促使下一个 micro-batch 的前向测算不用依靠上一个 micro-batch 的反方向测算,因而能够 畅行无阻的开展下来(自然在一个大 batch 的最后一次 micro-batch 依然会开启这一依靠)。
2.5 解决困难
Gradient Accumulation 解决了许多难题:
在单卡下,Gradient Accumulation 能够 将一个大的 batch size 拆分为等额的的众多小 micro-batch ,进而实现节约显卡内存的目地。
在数据信息并行处理下,Gradient Accumulation 解决了反方向梯度方向同歩花销占有率过大的难题(伴随着设备数和机器设备数的提升,梯度方向的 AllReduce 同歩花销也增加),由于梯度方向同歩变成了一个稀少实际操作,因而能够 提高数据信息并行处理的加快比。
在生产流水线并行处理下, Gradient Accumulation 促使不一样 stage 中间能够 并行执行不一样的 micro-batch,根据好几个 micro-batch的梯度方向累积促使下一个 micro-batch 的前向测算不用依靠上一个 micro-batch 的反方向测算,因而进而让每个环节的估算不堵塞,能够 畅行无阻的开展下来(自然在一个大 batch 的最后一次 micro-batch 依然会开启这一依靠), 做到生产流水线的目地。
0x03 PyTorch 梯度方向积累
3.1 全自动积累
PyTorch默认设置 会对梯度方向开展累积。即,PyTorch会在每一次backward()后开展梯度方向测算,可是梯度方向不容易全自动归零,如果不开展手动式归零得话,梯度方向会持续累积.
对于为何PyTorch有这种的特性,https://discuss.pytorch.org/t/why-do-we-need-to-set-the-gradients-manually-to-zero-in-pytorch/4903/9 这儿列出了一个表述。大家融合别的的表述大概得到以下:
从PyTorch的结构设计上而言,在每一次开展前向测算获得估计值时,会造成一个用以梯度方向传回的计算图,这幅图存储了开展反向传播必须的正中间結果,当启用了.backward()后,会从运行内存里将这幅图开展释放出来。
运用梯度方向累积,能够在数最多储存一张计算图的情形下开展多个任务的训炼。在多个任务中,对前边共享资源的偏微分开展了数次测算实际操作后,启用不一样工作的backward(),这些偏微分的梯度方向会全自动累积。
此外一个原因便是在内存空间不足的情形下累加好几个batch的grad做为一个大batch开展迭代更新,由于二者获得的梯度方向是等价关系的。
因为PyTorch的动态图片和autograd体制,造成 并没有一个准确的点了解什么时候终止前向实际操作,由于你永远不知道何时一个测算会完毕及其何时又有一个新的起点。因此 全自动设定梯度方向为 0 较为繁杂。
3.2 编码实例
下边得出一个传统式编码实例:
for i,(images,target) in enumerate(train_loader): # 1. input output images = images.cuda(non_blocking=True) target = torch.from_numpy(np.array(target)).float().cuda(non_blocking=True) outputs = model(images) loss = criterion(outputs,target) # 2. backward Optimizer.zero_grad() # reset gradient loss.backward() optimizer.step()
随后得出一个梯度方向积累实例:
获得loss: 键入图象和标识,根据测算获得估计值,测算损失函数;
loss.backward()反向传播,测算当今梯度方向;数次循环系统流程 1-2, 不清除梯度方向,使梯度方向累积在现有梯度方向上;
梯度方向累积一定频次后,先
optimizer.step()依据积累的梯度方向升级互联网主要参数,随后optimizer.zero_grad()清除往日梯度方向,为下一波梯度方向累积做准备;
for i, (images, target) in enumerate(train_loader): # 1. input output images = images.cuda(non_blocking=True) target = torch.from_numpy(np.array(target)).float().cuda(non_blocking=True) outputs = model(images) # 前向散播 loss = criterion(outputs, target) # 测算损害 # 2. backward loss.backward() # 反向传播,测算当今梯度方向 # 3. update parameters of net if ((i 1)�cumulation)==0: # optimizer the net optimizer.step() # 升级互联网主要参数 optimizer.zero_grad() # reset grdient # 清除往日梯度方向
3.3 DistributedDataParallel 的梯度方向积累
DistributedDataParallel(DDP)在module级别完成数据信息并行性。其应用torch.distributed包communication collectives来同歩梯度方向,主要参数和缓冲区域。并行性在单独过程內部和跨过程均有效。
在这样的情形下,尽管gradient accumulation 也一样能够 运用,可是为了更好地提高工作效率,必须 做对应的调节。
3.3.1 单卡实体模型梯度方向总计
大家最先追忆单卡实体模型,即一般状况下怎样开展梯度方向累积。
# 单卡方式,即一般状况下的梯度方向累积 for data in enumerate(train_loader # 每一次梯度方向累积循环系统 optimizer.zero_grad() for _ in range(K): prediction = model(data / K) loss = loss_fn(prediction, label) / K loss.backward() # 累积梯度方向,不运用梯度方向更改,实行K次 optimizer.step() # 运用梯度方向升级,升级互联网主要参数,实行一次
在 loss.backward() 句子处,DDP会开展梯度方向通信规约 all_reduce。
由于每一次梯度方向累积循环系统当中有K个流程,因此有K次 all_reduce。但事实上,每一次梯度方向累积循环系统中,optimizer.step()仅有一次,这代表大家这K次 loss.backward() 当中,实际上只开展一次 all_reduce 就可以,前边 K - 1 次 all_reduce 是没有用的。
3.3.2 DDP怎样加快
因此大家就思索,是不是能够 在 loss.backward() 当中有一个电源开关,促使我们在前边K-1次 loss.backward() 当中只做反向传播,不做梯度方向同歩(积累)。
DDP 早已想起了这个问题,它给予了一个临时撤销梯度方向同歩的context涵数 no_sync()。在no_sync()context下,DDP不容易开展梯度方向同歩。可是在no_sync()前后文完毕以后的第一次 forward-backward 会开展同歩。
最后编码以下:
model = DDP(model) for data in enumerate(train_loader # 每一次梯度方向累积循环系统 optimizer.zero_grad() for _ in range(K-1):# 前K-一个step 不开展梯度方向同歩(积累梯度方向)。 with model.no_sync(): # 这儿执行“不实际操作” prediction = model(data / K) loss = loss_fn(prediction, label) / K loss.backward() # 累积梯度方向,不运用梯度方向更改 prediction = model(data / K) loss = loss_fn(prediction, label) / K loss.backward() # 第K个step 开展梯度方向同歩(积累梯度方向) optimizer.step() # 运用梯度方向升级,升级互联网主要参数
3.3.3 no_sync完成
no_sync 的源代码以下:
@contextmanager def no_sync(self): r""" A context manager to disable gradient synchronizations across DDP processes. Within this context, gradients will be accumulated on module variables, which will later be synchronized in the first forward-backward pass exiting the context. Example:: >>> ddp = torch.nn.parallel.DistributedDataParallel(model, pg) >>> with ddp.no_sync(): >>> for input in inputs: >>> ddp(input).backward() # no synchronization, accumulate grads >>> ddp(another_input).backward() # synchronize grads """ old_require_backward_grad_sync = self.require_backward_grad_sync self.require_backward_grad_sync = False try: yield finally: self.require_backward_grad_sync = old_require_backward_grad_sync
实际怎么使用?我们在 DistributedDataParallel 的 forward 方式 中还可以见到,仅有在 require_backward_grad_sync 为 True情况下,才会启用reducer.prepare_for_forward() 和 reducer.prepare_for_backward,才会把require_forward_param_sync 设定为 True。
def forward(self, *inputs, **kwargs):
with torch.autograd.profiler.record_function("DistributedDataParallel.forward"):
self.reducer.save_thread_local_state()
if torch.is_grad_enabled() and self.require_backward_grad_sync:
# True情况下才会进到
self.logger.set_runtime_stats_and_log()
self.num_iterations = 1
self.reducer.prepare_for_forward() # 省去一部分编码
if torch.is_grad_enabled() and self.require_backward_grad_sync:
# True情况下才会进到
self.require_forward_param_sync = True
if self.find_unused_parameters and not self.static_graph:
# Do not need to populate this for static graph.
self.reducer.prepare_for_backward(list(_find_tensors(output)))
else:
self.reducer.prepare_for_backward([])
else:
self.require_forward_param_sync = False
# 省去一部分编码再看一下 Reducer的两种方式 。
prepare_for_forward 仅仅做统计工作总结,能够 忽视。
void Reducer::prepare_for_forward() {
std::lock_guard<std::mutex> lock(mutex_);
num_iterations_ ;
if (should_collect_runtime_stats()) {
record_forward_compute_start_time();
}
}prepare_for_backward 会做重设和筹备工作,与梯度方向积累有关的是 expect_autograd_hooks_ = true。
void Reducer::prepare_for_backward(
const std::vector<torch::autograd::Variable>& outputs) {
std::lock_guard<std::mutex> lock(mutex_);
// Reset accounting.
expect_autograd_hooks_ = true; // 这儿是重要
reset_bucket_counting();
// Reset unused parameter accounting.
has_marked_unused_parameters_ = false;
// Reset per iteration marked ready parameters.
perIterationReadyParams_.clear();
// If static graph is not set, search graph to detect unused parameters.
// When static graph is set, unused_parameters_ will be detected and will
// not change after 1st iteration.
// If static_graph_ = false and find_unused_parameters_ is false,
// we assume that autograd hooks for ALL variables will be called,
// and we don't have to search the autograd graph for presence of these hooks.
if (dynamic_graph_find_unused()) {
unused_parameters_.clear();
search_unused_parameters(outputs);
}
}expect_autograd_hooks_ = true 怎么使用?在 Reducer::autograd_hook 当中有,假如不用开展all-reduce实际操作,则立即回到。
void Reducer::autograd_hook(VariableIndex index) {
std::lock_guard<std::mutex> lock(this->mutex_);
// Carry over thread local state from main thread. This allows for
// thread-local flags such as profiler enabled to be configure correctly.
at::ThreadLocalStateGuard g(thread_local_state_);
// Ignore if we don't expect to be called.
// This may be the case if the user wants to accumulate gradients
// for number of iterations before reducing them.
if (!expect_autograd_hooks_) { // 假如不用开展all-reduce实际操作,则立即回到。
return;
}
// 省去事后编码有点儿绕,大家整理一下:
一个 step 有两个实际操作:forward 和 backward。
forward 实际操作情况下 :require_backward_grad_sync = True 代表着 forward 情况下
设定 require_forward_param_sync = True。
会启用reducer.prepare_for_forward() 和 reducer.prepare_for_backward
reducer.prepare_for_backward 代表着会设定 expect_autograd_hooks_ = true,expect_autograd_hooks_是重要。
backward 实际操作情况下 :
expect_autograd_hooks_ = true 代表着 backward 情况下开展 开展all-reduce实际操作。
不然立即回到,不做 all-reduce实际操作。
即如下图,
上边部份是 forward 的逻辑性,便是 forward()涵数,
下半部份是 backward 逻辑性,便是 Reducer::autograd_hook() 涵数。
expect_autograd_hooks_ 是forward 和 backward 中间串接的重要之处。
forward --------------------------------------------------------------------------------- | forward() | | | | require_backward_grad_sync == True?? --------- | | | | | | | | | | Yes | | | | | No | | v | | | reducer.prepare_for_forward | | | | | | | | | | | | | | v | | | reducer.prepare_for_backward | | | | | | | | | | | | | | v v | | expect_autograd_hooks_ = true expect_autograd_hooks_ = false | | | | | | | --------------------------------------------------------------------------------- | | -------------------------------------------------------------------------------- backward | | | | -------------------------------------------------------------------------------- | | | | | Reducer::autograd_hook() | | | | | | | | | ---------------------------- | | | | | | | | | | v v | | expect_autograd_hooks_ == True?? ------------ | | | | | | Yes | | | | | No | | v v | | Do All-Reduce Return | | | | | --------------------------------------------------------------------------------
no_sync 实际操作就 代表着设定 require_backward_grad_sync = False,最后设定了 expect_autograd_hooks_ = False。那样,backward 情况下就不易开展 All-Reduce 实际操作。
0x04 Tensorflow完成
在 pytorch 中,梯度方向只需不清零默认设置 是叠加的,因此非常容易完成以上难题。但在Tensorflow中,却不那麼非常容易。
大家从 stackoverflow 获得实例编码以下:
## 界定优化器 opt = tf.train.AdamOptimizer() ## 获得你实体模型中的全部可训炼自变量 tvs = tf.trainable_variables() # 用以纪录每一个自变量的积累梯度方向,复位为0s accum_vars = [tf.Variable(tf.zeros_like(tv.initialized_value()), trainable=False) for tv in tvs] # 界定清零实际操作 zero_ops = [tv.assign(tf.zeros_like(tv)) for tv in accum_vars] ## 应用优化器的compute_gradients来估算梯度方向 gvs = opt.compute_gradients(rmse, tvs) ## 将当今梯度方向累积在以前界定的自变量上 accum_ops = [accum_vars[i].assign_add(gv[0]) for i, gv in enumerate(gvs)] ## 界定训炼step,梯度下降法,升级主要参数 train_step = opt.apply_gradients([(accum_vars[i], gv[1]) for i, gv in enumerate(gvs)]) ## 训炼循环系统 while ...: # 应用 zero_ops 复位 sess.run(zero_ops) # 应用accum_ops对accum_vars开展'n_minibatches'次梯度积累 for i in xrange(n_minibatches): sess.run(accum_ops, feed_dict=dict(X: Xs[i], y: ys[i])) # 应用积累的系数开展主要参数升级 sess.run(train_step)
0x05 Gpipe完成
在 GPipe 的水流并行处理实例中,每一个“时间点” 能够 在好几个环节(stage)上与此同时做不一样的micro-batch,图上每一个格子中的型号表明了几个 micro-batch;同一个 micro-batch 或是串行通信的历经任何的 stage,在这样的情形下,每一个设施的空闲时间仅有 25% 上下。
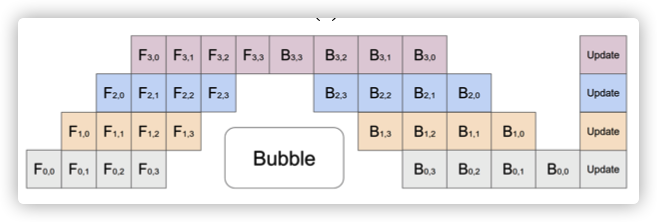
实际编码以下:
5.1 优化器
在 lingvo/core/optimizer.py 中 GradientAggregationOptimizer 中有实际完成,重要编码为apply_gradients,逻辑性为:
假如 _num_micro_batches 为 1,则表明无需梯度方向积累,立即 apply_gradients;
解析xml grads_and_vars 目录,积累梯度方向;
accum_step 为梯度方向积累标准:
启用 apply_gradients 运用梯度方向;
启用 zero_op 清零梯度方向;
假如实现了小批号迭代更新数量,则启用 _ApplyAndReset:
不然就启用_Accum,事实上是 no_op不做实际操作;
实际编码以下:
def apply_gradients(self, grads_and_vars, global_step=None, name=None): if self._num_micro_batches == 1: return self._opt.apply_gradients(grads_and_vars, global_step) global_step = global_step or py_utils.GetOrCreateGlobalStepVar() with tf.init_scope(): self._create_slots([v for (_, v) in grads_and_vars]) accums = [] variables = [] # 解析xml,积累梯度方向 for g, v in grads_and_vars: accum = self.get_slot(v, 'grad_accum') variables.append(v) # pytype: disable=attribute-error if isinstance(g, tf.IndexedSlices): scaled_grad = tf.IndexedSlices( g.values / self._num_micro_batches, g.indices, dense_shape=g.dense_shape) else: scaled_grad = g / self._num_micro_batches accum_tensor = accum.read_value() accums.append(accum.assign(accum_tensor scaled_grad)) # pytype: enable=attribute-error # 运用梯度方向,清零梯度方向 def _ApplyAndReset(): normalized_accums = accums if self._apply_crs_to_grad: normalized_accums = [ tf.tpu.cross_replica_sum(accum.read_value()) for accum in accums ] apply_op = self._opt.apply_gradients( list(zip(normalized_accums, variables))) with tf.control_dependencies([apply_op]): zero_op = [tf.assign(accum, tf.zeros_like(accum)) for accum in accums] return tf.group(zero_op, tf.assign_add(global_step, 1)) # 积累涵数,实际上不是做实际操作 def _Accum(): return tf.no_op() # 梯度方向积累标准,假如实现了小批号迭代更新数量,则运用梯度方向,清零梯度方向,不然也不做实际操作 accum_step = tf.cond( tf.equal( tf.math.floormod(self._counter 1, self._num_micro_batches), 0), _ApplyAndReset, # Apply the accumulated gradients and reset. _Accum) # Accumulate gradients. with tf.control_dependencies([tf.group(accums)]): return tf.group(accum_step, tf.assign_add(self._counter, 1))
5.2 包裝器
ShardedAdam 是给 GradientAggregationOptimizer 和 ShardedAdamOptimizer 干了包裝,客户能够立即应用。
class ShardedAdam(optimizer.Adam):
"""Adam optimizer wrapper that shards the slot variables."""
@classmethod
def Params(cls):
params = super().Params()
params.Define('num_micro_batches', 1, 'Number of accumulated batches.')
return params
def GetOptimizer(self, lr):
p = self.params
opt = ShardedAdamOptimizer(
learning_rate=lr,
beta1=p.beta1,
beta2=p.beta2,
epsilon=p.epsilon,
name=p.name)
if p.num_micro_batches > 1:
tf.logging.info('Applying gradient aggregation.')
opt = optimizer.GradientAggregationOptimizer( # 运用梯度方向积累
opt, p.num_micro_batches, apply_crs_to_grad=True)
self._cached_opt = opt
return opt5.3 运用
DenseLm12kWide41BAdam16x16 中有怎么使用 ShardedAdam。
@model_registry.RegisterSingleTaskModel class DenseLm12kWide41BAdam16x16(DenseLm128B16x16): """41B params LM model with 2D split and ADAM optimizer on v3-512.""" # Each layer has 1.6875B parameters. SEQUENCE_LENGTH = 2048 NUM_DEVICES_PER_SPLIT = 512 BATCH_DIM_PER_DEVICE = 0.5 # Total batch size 256 DEVICE_MESH_SHAPE = [16, 32] DEVICE_MESH = gshard_utils.GetNonPod2dMesh(DEVICE_MESH_SHAPE, [16, 16, 2]) NUM_TRANSFORMER_LAYERS = 24 HIDDEN_DIM = 48 * 1024 MODEL_DIM = 12 * 1024 NUM_HEADS = 96 ATTENTION_KEY_VALUE_DIM = 128 GATED_GELU = False POSITIONAL_EMBEDDING = True NUM_MICRO_BATCHES = 1 def Task(self): p = super().Task() # 应用ShardedAdam p.train.optimizer = ShardedAdam.Params().Set( beta1=0.9, beta2=0.999, epsilon=1e-6, num_micro_batches=self.NUM_MICRO_BATCHES) return p



